【論文読み】A Survey on Visual Transformer 日本語まとめ,論文リンク
Transformerは、NLPの分野で大きな成功を収め、近年CV(Computer Vision)の分野にも応用されている。TransformerのCV分野への応用についてのsurvey論文であるKai Hanらの"A Survey on Visual Transformer“を読んでまとめた。(間違っている所があればご指摘ください。論文のリンクはつけていないところもあります。このページの需要があれば追記します。)
論文に書いていない、自分で調べた事項については*(アスタリスク)をつけている。
概要
- Transformerは最初にNLP(自然言語処理)の分野で応用され、数多くのベンチマークでCNN,RNNを超える成果をあげた。
- 近年はこれらの成功からComputer Visionの分野でも注目を集めている。
- この論文では、TransformerをCVの分野に応用したときの利点と欠点についてまとめた。
- 実際のデバイスにアプリケーションとして実装するときの効果的な手法についても分析する。
- 今後のVisual Transformerの研究の方向性についても議論を行う。
1.Introduction
NLPの分野で、Transformerが導入され多くのモデルで成功を収めた。
NLPでの成功を受けてCVの分野でも適用する動きが出てきた。
- pixelsの自己回帰モデルに適用し、CNNを凌駕。
- ViT
- 純粋なtransformerモデルを画像パッチのシーケンスに直接適用。
- 複数の画像認識ベンチマークでSOTA
transformerを様々なCVのタスクに利用する研究が進んでいる。
- Backbone
- Image classification
- iGPT(ICML 2020)
- GPT modelを用いて、Pixel予測の自己教師学習
- ViT(ICLR 2021)
- 画像パッチ、標準変換器
- iGPT(ICML 2020)
- Image classification
- High/Mid-level vision
- Object detection
- DETR(ECCV 2020)
- セットベースの予測、bipartite matching(2部マッチング)、transformer
- Deformable DETR(ICLR 2021)
- DETR, 変換可能なAttentionモジュール
- ACT(arXiv 2020)
- 適応型クラスタリングtransformer
- UP-DETR(arXiv 2020)
- 教師なしの事前学習、ランダムなクエリパッチの検出
- TSP(arXiv 2020)
- 新しい2部マッチング、エンコーダのみのtransformer
- DETR(ECCV 2020)
- Segmentation
- Max-DeepLab(arXiv 2020)
- PQ-styleの2部マッチング、デュアルパスtransfomer
- VisTR(arXiv 2020)
- インスタンスシーケンスのマッチングとセグメンテーション
- SETR(arXiv 2020)
- シーケンスからシーケンスへの予測、standard transformer
- Max-DeepLab(arXiv 2020)
- Pose Estimation
- Hand-Transfomer(ECCV 2020)
- 非自動回帰transfomer, 3次元ポイントセット
- HOT-Net(MM 2020)
- 構造参照抽出器
- METRO(arXiv 2020)
- プログレッシブ次元削減
- Hand-Transfomer(ECCV 2020)
- Object detection
- Low-level vision
- Image enhancement
- IPT(arXiv 2020)
- マルチタスク、ImageNet pre-training、transfomer model
- TTSR(CVPR 2020)
- Texture transformer, RefSR
- IPT(arXiv 2020)
- Image generation
- Image Transformer(ICML 2018)
- transformerを使用したPixel生成
- Image Transformer(ICML 2018)
- Image enhancement
- Video processing
- Video inpainting
- STTN(ECCV 2020)
- 時空間敵対損失
- STTN(ECCV 2020)
- Video captioning
- Masked Transformer(CVPR 2018)
- Masking network, イベント提案
- Masked Transformer(CVPR 2018)
- Video inpainting
- Efficient transformer
- Decomposition
- ASH(NeurIPS 2019)
- ヘッドの数、重要度推定
- ASH(NeurIPS 2019)
- Distillation
- TinyBert(EMNLP Findings 2020)
- モジュールごとの様々な損失
- TinyBert(EMNLP Findings 2020)
- Quantization
- FullyQT(EMNLP Findings 2020)
- 完全に量子化されたtransformer
- FullyQT(EMNLP Findings 2020)
- Architecture design
- ConvBert(NeurIPS 2020)
- 局所依存性、動的畳込み
- ConvBert(NeurIPS 2020)
- Decomposition
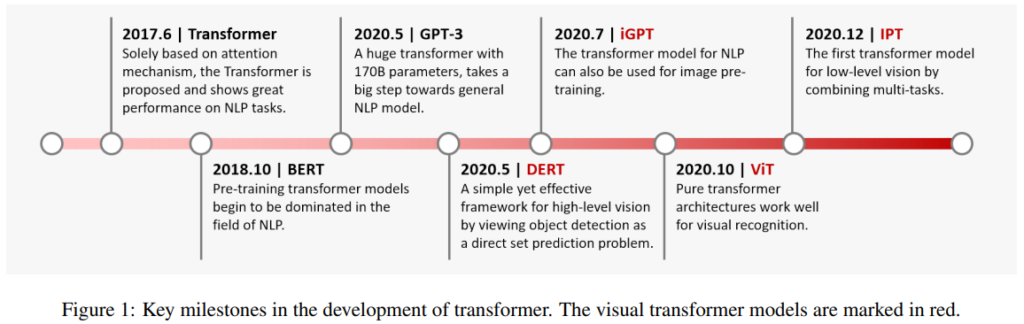
論文構成
section2: Transformerの数学的な公式
section3: TransformerのNLPでの利用
section4: visual transfomerについて
section5: まとめ、研究の方向性と課題について議論
2.Formulation of Transfomer
初めてTransformerが使われた論文を紹介Attention is all you need。
全体の構造は、以下のfigure 2の通り。
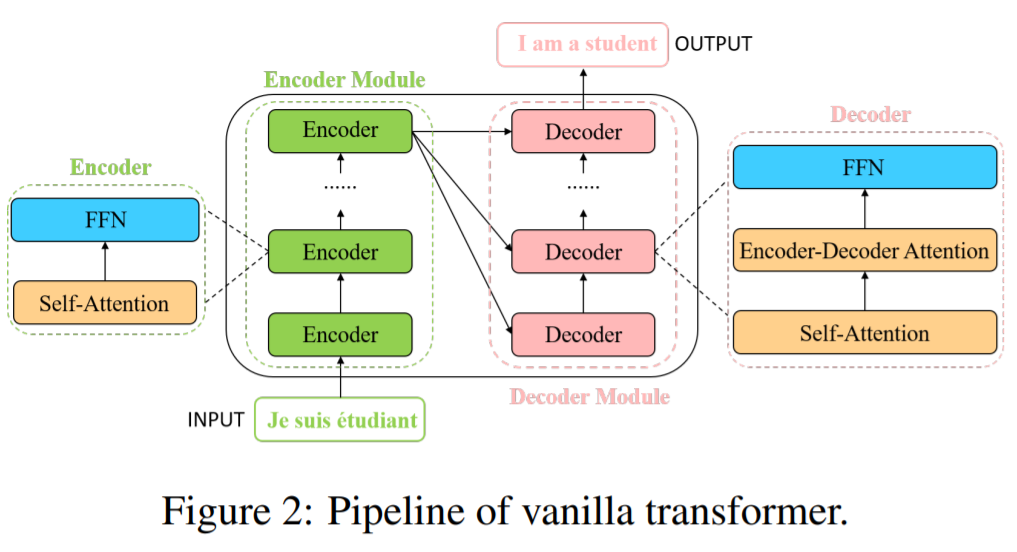
- Encoder module, Decoder moduleで構成。
- encoder, decoderどちらもself-attentionと順伝播NNで構成。
- decoderは、encoder-decoder attention layerも含んでいる。
- Transformerが文の翻訳に使えるように文中の各単語を$d_{model}=512$次元のベクトルに変換する必要あり。
2.1 Self-Attention Layer
入力は、3つの異なるベクトルに変換される。
- q: query vector
- k key vector
- v: value vector ($dq = dk = dv = d_{model} = 512$)
異なる入力から派生したベクトルは、3つの異なる行列にまとめられる。
これらをそれぞれQ,K,Vとして表す。
Attention関数において、異なる入力ベクトルは、次のように計算される。
- step1: 異なる入力ベクトル間のスコアを計算する。
- $S=QK^T$
- step2: 勾配を安定させるためにスコアを正規化する。
- S =$\frac{S}{\sqrt{d_k}}$
- step3: ソフトマックス関数を使用して、スコアを確率Pに変換する。
- $P = softmax(S_n)$
- step4: 重み付けされた値の行列を求める。
- Z = VP
以上のプロセスは、次の1つの関数に統合できる。
$$Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}}) \cdot V . (1)$$
より大きな確率をもつベクトルは、次の層から追加の注目を受けることになる。
decoder moduleのencoder-decoder attention layerは、
- キー行列 Kと値行列Vはエンコーダモジュールから派生したもの
- クエリ行列Qは、前の層から派生したもの
である例外を除きencoder moduleのself-attention layerと同様である。
Self-Attention layerは、文中の単語の位置情報を把握する能力が欠けている。
そこで、元の入力埋め込みに位置情報を加える。以下の式のように符号化する。
$$PE_{(pos, 2i)} = sin(\frac{pos}{10000^{\frac{2i}{d_model}}}); (2)$$
$$PE_{(pos, 2i + 1)} = cos(\frac{pos}{10000^{\frac{2i}{d_model}}}), (3)$$
posは文章での位置を表し、iは位置エンコーディングの現在の次元を表す。
(*原論文によるとこの関数を選んだのは、相対的な位置$PE_{pos+k}$を$PE_{pos}$の1次関数で表現可能であるかららしい。)
2.2 Multi-Head Attention
Multi-Head Attentionは、通常のself-attentionを拡張し、性能を向上させるメカニズム。構造は、以下のfigure3の通り。
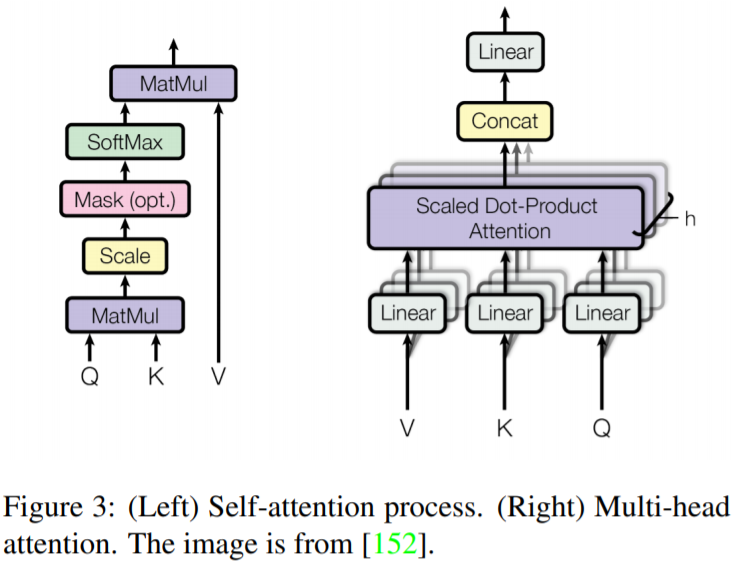
人間は文章を見るとき複数の単語に注目する。single-head self-attenitonでは、同時に重要な位置に注意を向けるための能力が制限される。
→attention layerに異なる表現部分空間を与えることによって改善
具体策: 異なるヘッドに対して、異なるquery, key, valueの行列を使用。
入力ベクトルとヘッドの数hが与えられたとき、入力ベクトルは、query, key, valueの3つの異なるブループに変換される。各グループには、
$d_{q’} = d_{k’} = d_{v’} = d_{model}/h = 64$
の次元を持つh個のベクトルがある(定数64で固定のため、modelの次元数とhの個数はトレードオフとなり、総パラメータ数は変わらない。)。異なる入力から得られたベクトルは、次の3つの異なるグループの行列にまとめられる。
$\{Q_i\}^h_{i=1}, \{K_i\}^h_{i=1}, \{V_i\}^h_{i=1}$
multihead atteniton プロセスは次のように示される。
$$MultiHead(Q’, K’, V’) = Concat(head_1, … , head_h)W^o, \\ where head_i = Attention(Q_i, K_i, V_i). (4)$$
$Q’$(同様に$K’, V’$)は、${Q_i}^h_{i=1}$の連結である。そして、$W^o \in \mathbb{R}^{d_{model} \times d_{model}}$は線形射影行列である。
2.3. Other Key Concepts in Transformer
- エンコーダーとデコーダーにおける残差接続
- figure 4のように、エンコーダーとデコーダーの各サブレイヤには、残差接続が追加
- 接続の後には、層の正規化を行う。
- $LayerNorm(X + Attention(X)). (5)$
- Xはself-attention layerの入力として使用される。
(クエリ行列、キー行列、値行列Q, K, Vがすべて同じ入力行列Xから得られるから)
- Xはself-attention layerの入力として使用される。
- Feed-Forward Network
- 各エンコーダとデコーダのself-attention layerの後に適用される。
- 2つの線形変換層とその中の非線形活性化関数で構成
- $FFN(X) = W_2\sigma(W_1, X). (6)$
- $W_1$と$W_2$は2つの線形変換層の2つのパラメータ行列
- $\sigma$はGELUなどの非線形活性化関数を表す。
- 隠れ層の次元は、$d_h = 2048$
- Final Layer in the Decoder
- デコーダの最終層は、ベクトルのスタックをワードに戻すために使用される。
- 線形層とソフトマックス層によって実現
- 線形層はベクトルを$d_{word}$次元のlogits ベクトルに投影($d_{word}$は語彙の数)
- ソフトマックスは、logitsベクトルを確立に変換するために使用。
- 局所的な特徴にしか注目できないCNNと比較して、transfomerはグローバルな情報を獲得。
- 逐次計算が必要なRNNと異なり、並列計算も可能。
3. Revisiting Transfomers for NLP
Transformerの登場によって、グローバルな依存関係を捉えながら並列計算が可能になった。これによって、より大規模なデータセットでの学習が可能になり、自然言語処理のための大規模な事前学習済みモデル(PTMs)が急増している。
BERT
BERT及びその変種(SpanBERT、RoBERTaなど)は、multi-layer transfomer encoder 構造に基づいて構築された一連のPTMs(Pre Train Models)である。
BERTの事前学習段階において、BookCorpus及び、英語版Wikipediaデータセットを対象にした2つの課題が実施されている。
- Masked Language Modeling(MLM)
- 入力中のいくつかのトークンを無造作にマスキングし、それらを予測するためにモデルを学習する。
- Next Sentence Prediction
- 対になった文を入力として使用し、2番めの文が文書内の元の文であるかどうかを予測する。
事前学習後、BERTは、出力層を追加することによって広範囲の下流タスクについて微調整することができる。
BERTは、リリース時に11のNLPのタスクでSOTAを達成。
Generative Pre-trained Transformer model(GPT, GPT-2など)はマスクされたself-attention 構造を使用するtransfomer decoder 構造に基づくもう一種類のPTMsである。
BERTとGPTシリーズの違い。
- GPT
- LTR(Left-to-Right)言語モデリングを用いて事前学習(一方構成の言語モデル)
- (*BERTの論文によると、一方向だけの学習なので、文章タスクや、Q&Aなどの前後の文脈が重要なものでは有効ではないらしい。)
- BERT
- 文区切り(SEP)及び分類器トークン(CLS)の埋め込みを事前訓練中に学習(GPTでは微調整時のみ)。

BioNLP Domain
transformer baseのモデルは、多くの従来の生物医学的手法を凌駕している。
- 生物医学テキストマイニングタスク
- 科学領域におけるNLPタスクをより正確に実行するために科学記事を訓練
- 臨床ノートの連続的な表現を開発及び評価
Multi-Modal task
Multi-modal(動画テキスト、画像テキスト、音声テキスト)の処理におけるtransformerの可能性を活用する研究。
- CNNbaseのモジュールで動画の表現トークンを得て、transformer encoderで学習
- 視覚的質問応答(VQA)や視覚的常識推論(VCR)などの下流タスクのために視覚的要素や画像とテキストの関係を捉える。single-streamの統一されたtransformerを使用。
- 音声質問応答(SQA)なdの自動テキストタスク処理のために、音声とテキストのペアをtransformer encoderでencodeする可能性を探る。
4. Visual Transformer
4.1. Backbone for Image Classification
CNN以外にもTransformerは画像分類のbackbone networkとして使用できる。
Wuらは、ResNetをベースラインとして採用し、最終層をTransformerに置き換えた。
- 畳み込み層を適用して低レベルの特徴を抽出。
- visual transformerに供給。
- visual transformerでは、tokenizerを使用して、ピクセルを画像内の意味的概念を表す少数の視覚的トークンにグループ化。
- transfomerはトークン間の関係をモデル化するために使用。
transformerだけを使って画像分類をしたものとしてiGPT, ViT, DeiTがある。
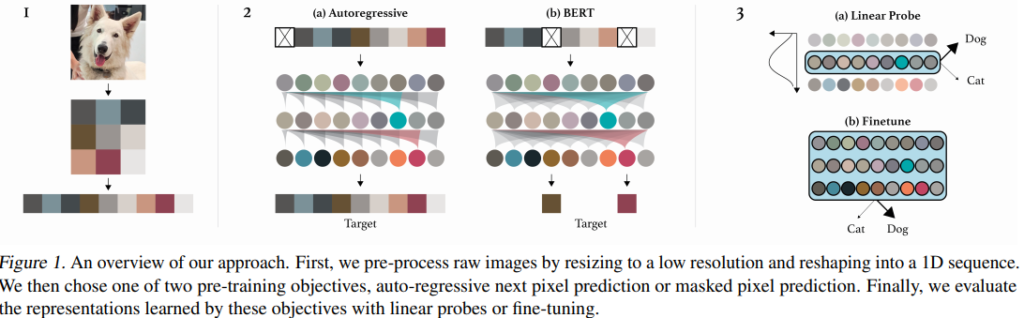
4.1.1. iGPT
iGPT(ICML 2020) ,Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever
- 画像に対する事前学習と自己教師付き手法を組み合わせた手法。
- 事前学習段階と微調整段階から構成される。
- ピクセル予測を実装するためにNLPで使用されるような言語トークンの代わりにsequence transformerを採用。
- 事前学習は、eary stoppingと組み合わせて使用するとよい。
- 微調整段階では、モデルに小さな分類ヘッドを追加
- 高次元のデータ$x = (x_1, …, x_n)$からなるラベルの無いデータセットXが与えられた場合、データの対数尤度を最小化することでモデルを学習する。
- $L_{AR} = \mathbb{E}_{x 〜 X}[-logp(x)] (7)$
p(x)は、画像データの密度で、次のようにモデル化できる。- $p(x) = \Pi ^n_{i=1} p(x_{\pi _i}|x_{\pi _1}, … , x_{\pi _{i-1}}, \theta) (8)$
- ここでは、$1 \leq i \leq n$に対して、同一の順列$\pi _i = i$が採用されている。
- $L_{AR} = \mathbb{E}_{x 〜 X}[-logp(x)] (7)$
- BERT mask M
- 各インデックスiが独立に0.15の確率でMに現れるような部分配列 $M \subset [1, n]$をサンプリング。
- モデルの学習
- 条件: マスクされていない要素$x_{[1,n]\backslash M}$
- 最小化する関数: マスクされている要素$x_M$の負の対数尤度
- $L_{BERT} = \mathbb{E}_{x\backslash X}\mathbb{E}_M\sum_{i \in M}{-logp(x_i | x_{[1, n]\backslash M})]} (9)$
- 事前学習段階では、LAR, LBERTのいずれかを選択し、事前学習データセットに対する損失を最小化する。
- transformer decoderブロックには、GPT-2(*GPTを更に巨大なデータセットで学習したもの)形式が用いられている。
- 特にlayer normは、attention, MLP操作の両方に先行し、すべての操作は厳密に残差パスで実行される。
- シーケンス要素間の混合を伴うのは、attention演算のみ。
- *式は原論文に以下のように示されていた。
- $n^l = layer_norm(h^l)$
- $a^l = h^l + multihead_attention(n^l)$
- $h^{l + 1} = a^l + mlp(layer_norm(a^l))$
- $h^l$: input tensor
- AR目的の学習時
- 適切な条件付を行うためにattention logitのnxn行列に標準上三角行列マスクを適用。
- BERT目的の学習時
- logitのマクスは必要ない。
- 入力シーケンスに内容埋め込みを適用したあと、Mの位置をゼロにする。
- マスクされていない位置にあるlogitを単純に無視する。
- *各シーケンス要素に対して独立した位置埋め込みを学習するため、位置の誘導バイアスがない(CNNのような近接特徴のバイアスとは対照的)。
- 最終層では、ノルムを適用し、各配列要素における条件付分布をパラメータ化するlogitsへの$n_L$からの投影を学習する。
- * $n^L = layer_norm(h^L)$
- Fine-tuning 段階
- 最終層の出力事前全体の$n^L$をaverage poolingして、下の例ごとに特徴量のd次元ベクトルを抽出する。
- $f^L = {\langle n_i^L \rangle }_ i$
- $f^L$からclass logitsへの投影を学習し、cross entopy loss $L_{CLF}$を最小化する。
- 経験的には、目的$L_{GEN}+L_{CLF}, L_{GEN} \in \{ L_{AR}, L_{BERT}\}$がよりよく機能する。
4.1.2 ViT
An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale, Dosovitskiy et al
ViTは画像パッチのシーケンスに直接適用したときに、画像分類タスクで優れた性能を発揮するtransformer.モデルの概要は以下のfigre5.
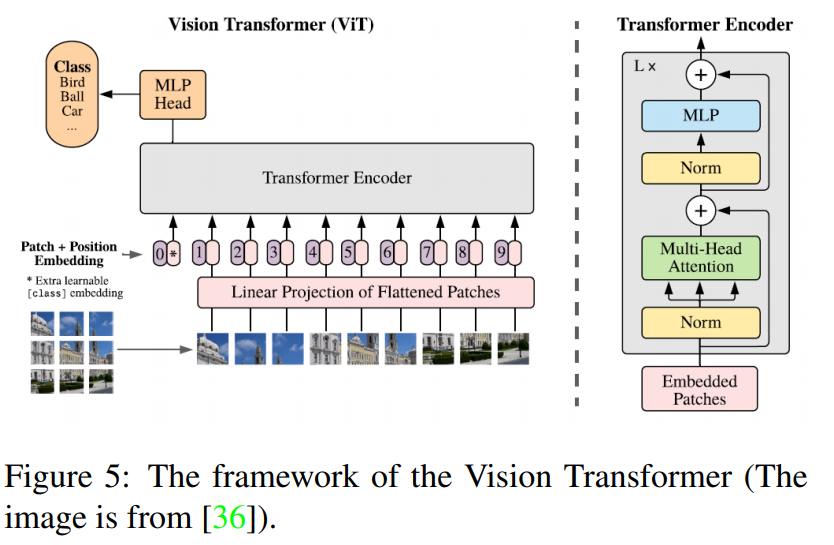
2D画像の扱い方
- 入力画像: $x\in \mathbb{R}^{H \times W \times C}$
- 平坦化された2Dパッチのシーケンス$x_p \in \mathbb{R}^{N \times (P^2 \cdot C)}$に再成形
- (H,W): 原画像の解像度
- (P,P): 各画像パッチの解像度
- 有効なシーケンス長: $N=HW/P^2$
- すべての層で一定の幅を使用し、ベクトル化された各パスがモデル次元Dにマッピングされる。この出力を埋め込みパッチ(patch embeddings)と呼ぶ。
- BERTのclass tokenと同じように、学習可能な埋め込みは埋め込みパッチのシーケンスに適用される。
- pretrain , fine-tuningの両方で分類ヘッドは同じサイズにつけられる。
- 位置情報保持のために、埋め込みパッチに1次元の位置埋め込み(position embeddings)を追加
- 2次元を意識した埋め込みも考えたが、1次元と比べて大きな効果は得られなかった。
- 結合された埋め込みはエンコーダへの入力となる。
- 事前に大規模データセットで学習した後、下流の小規模タスクに微調整される。
- 事前学習した予測ヘッドを取り除きゼロ初期化されたDxKフィードフォワード層を追加。
- 微調整段階で事前学習段階よりも高解像度の使用すると、しばしば有益。
- 任意のシーケンス長を扱えるが、事前学習が意味をなさなくなる可能性もあるので、事前学習した位置埋め込みを原画像内の位置に応じて2次元補完している(手動バイアス)。
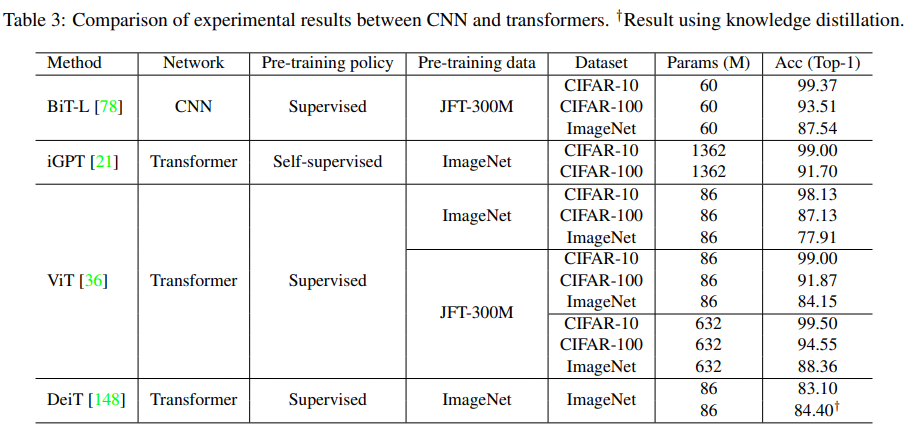
- ImageNetのような中規模データセットで学習したとき、同サイズのResNetsよりも数%point低い。
- JFT300M等、大規模なデータセットで学習したときは優れた結果。
- Touvron らはImageNetデータベースのみで学習することにより、Data-efficient image transfomrer(DeiT)を提案。
- DeiTBはViT-Bと同じ構造で、8600万個のパラメータを用いている。
- 強力なデータ増強で外部データ無しでImageNet上で83.1%のtop1 acc
- CNN教師を用いたトークンベースの蒸留を行うことでDeiT-Bは84.40%top1 acc
まとめ
- iGPTは生成的な事前学習法を自己教師付き手法と組み合わせたが、結果は満足の行くものではなかった。
- ViTは、特に大規模なデータセット(JFT-300M)を利用した場合、良い結果。
- DeiTは、より慎重な学習戦略と、トークンベースの蒸留によって良い成果。
4.2 High/Mid-level Vision
近年、物体検出、車線検出、セグメンテーション、pose推定などのHigh/Mid-level のCVタスクにtransformerを用いることが注目されている。
4.2.1 Generic Object Detection
Transformerを用いた物体検出手法
- self-attentionを利用して、特徴融合モジュール、予測ヘッドなど、特定のモジュールの強化(4.5で後述)
Transformer baseの物体検出手法は、大きく2つに分けられる。
- transformer baseの集合予測法(transformer-based set prediction methods)
- transformer baseのバックボーン法(transformer-based backbone methods)
それぞれの構造は以下のFig6のようになっている。
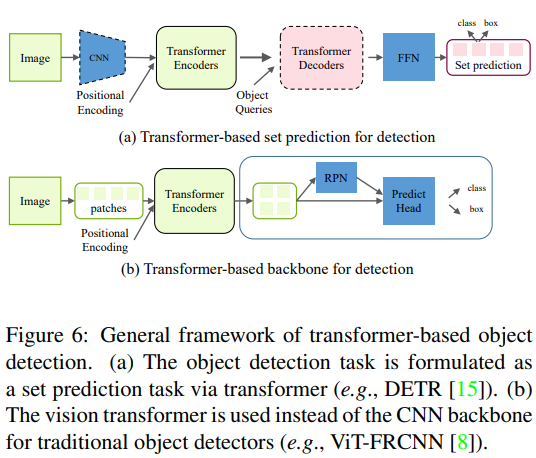
Transformer-based Set Prediction for Detection
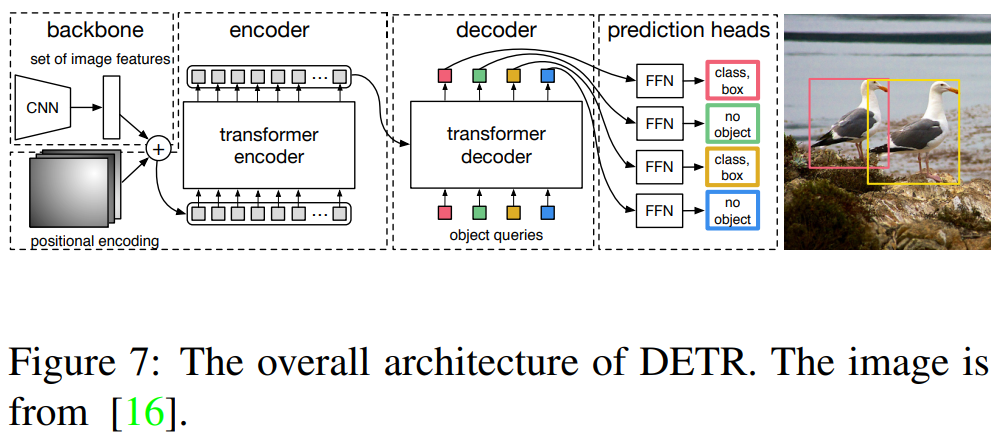
Transformer base の物体検出の先駆けは、Carionらによって提案されたthe detection transformer(DETR)である。
- 完全なend-to-endの物体検出器
- 物体検出タスクを直感的なセット予測問題として扱い、アンカー生成やNMS(non-maximum suppression)後処理を排除。
- fig7のように、CNN backboneで入力画像の特徴量を抽出。
- 画像の位置情報付加のために、特徴が、encoder-decoder transformerに供給される前に平坦化された特徴に固定位置encodeが追加される。
- decoderはencoderからの埋め込みと、N個の学習済み位置encoding(object queries)を消費し、N個の出力埋め込みを生成する。
- Nは事前に定義されたパラメータで、通常は画像内の物体の数よりも大きい。
- 最終的な予測値を計算するために単順なfeed-forward networkが使用される。
- bboxの座標と、物体の特定のクラスを示すクラスラベルが含まれる。
- 予測値を逐次計算するオリジナルのtransformerと違い、DETRは、N個の物体を並行してDecodeする。
- 予測された物体と正解の物体を割り当てるためにbipartite matching algorithmを採用している。
- 式11に示すように、Hungarian lossを利用してすべてのマッチした物体のベアの損失関数を計算する。
- $\mathcal{L}_{hungarian}(y, \hat{y}) = \sum_{i=1}^N \left[ -\log{\hat{p}_{\hat{\sigma}(i)}}(C_i) + \mathbb{1}_{\{c_i \neq \phi\}} \mathcal{L}_{box}(b_i, \hat{b}_{\hat{\sigma}}(i)) \right], (11)$
- $y$: 物体の正解
- $\hat{y}$: 物体の予測
- $\hat{\sigma}$: 最適な割当
- $c_i$: ターゲットクラスラベル
- $\hat{p}_{\hat{\sigma}(i)}(C_i)$: 予測ラベル
- $b_i$: 正解のbbox
- $\hat{b}_{\hat{\sigma}}(i)$: 予測のbbox
- $\mathcal{L}_{hungarian}(y, \hat{y}) = \sum_{i=1}^N \left[ -\log{\hat{p}_{\hat{\sigma}(i)}}(C_i) + \mathbb{1}_{\{c_i \neq \phi\}} \mathcal{L}_{box}(b_i, \hat{b}_{\hat{\sigma}}(i)) \right], (11)$
- 式11に示すように、Hungarian lossを利用してすべてのマッチした物体のベアの損失関数を計算する。
- Faster R-CNNベースラインと同等の精度と速度を実現。
DETRの課題
- 訓練スケジュールの長さ
- 小さな物体に対する性能が低い
課題解決のためにZhuらがDeformable DETRを提案
Deformable attention modleが用いられる。
- 従来のtransformer: multihead attention で画像特徴マップ上のすべての空間的位置を見る。
- Deformable attention module: 基準点の周りの小さなキーポジションのセットに注目する。
- 計算の複雑さが大幅に軽減(DETRよりも10倍少ない学習コスト)
- 収束も早くなる。(DETRより1.6倍早い推論速度)
- マルチスケールの特徴を融合するために容易に適用できる。
- iterative bounding box refinement method と twostage schemeを用いて更に性能を向上。
ZhengらはAdaptive Clustering Transformer(ACT)を提案
ACTは、事前に学習されたDETRの計算コストを学習プロセスなしに削減する。
- Locality Sensitivity Hashing(LSH)法を用いてクエリの特徴を適応的にクラスタリングし、選択されたプロトタイプで表されるクエリに注目出力をブロードキャストする。
- 事前に訓練されたDETRのself-attention moduleを置き換えるために使用され、再学習を必要としない。
- 計算コスト大幅削減。
- 精度は僅かに低下するだけ。
- multi-task knowledge distillation (MTKD)法を使うことで数エポックの微調整で、オリジナルのTransformerからACT moduleを蒸留できる。
- 性能低下を更に抑える。
Sunらは、Rethinking Transformer-based Set Prediction for Object DetectionでDETRモデルの収束が遅い理由を調査。
- 主な原因:transformer decoder のcross-attention module
- 解決策: encoderのみのDETRを提案。
- 検出精度、学習収束性の点で大幅改善。
更に学習の安定性と収束の速さを向上させるために提案。
- 新しいbipartite matching scheme を提案。
- 特徴ピラミッドを用いたencoderのみのDETRを改良するために2つのtransformer baseのセット予測モデル提案。
- TSP-FCOS
- TSPRCNN
Daiらは、NLPにおけるpre-training transformer スキームにヒントを得て、unsupervised pre-training for object detection(UP-DETR)を提案。
- DETRモデルを事前学習するために、ランダムクエリパッチ検出という新しい教師なし学習タスクが提案。
- 比較的小さなデータセット(PASCAL VOC)での検出精度を大幅に向上。
- COCO benchmarkでもDETRよりも優れた性能。
Transformer-based Backbone for Detection
- DETR: transformerを介した一連の予測タスクとして再設計。
- Beal らのViT-FRCNN: Faster R-CNNのような一般的な検出フレームワークのbackboneとしてtransformerを利用することを提案。
- 入力画像はいくつかのパッチに分割されてvisual transformerに入力
- 出力埋め込み特徴を空間情報に従って再構成。
- 検出ヘッドを通過して最終的な結果を得る。
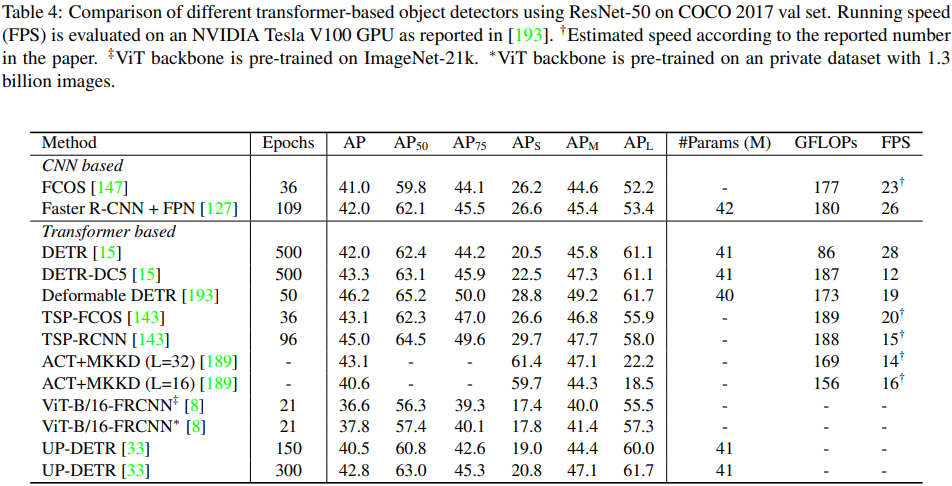
COCO 2012のデータセットを用いた様々なtransformer baseの物体検出の検出結果(Table4)。
4.2.2 Other Detection Tasks
Pedestrian Detection(歩行者検出)
オクルージョン、群衆シーンなど物体の分布が密なときは、一般的な物体検出モデルを歩行者検出タスクに適用する場合、追加の分析と適応が必要になることが多い。
LinらはDETRやDeformable DETRを歩行者検出タスクに直接適用した場合、一様なクエリが疎であることや、decoderのatteniton filedが弱いことが性能低下につながることを明らかにした。(DETR for Crowd Pedestrian Detection)
- DQRF(Dense Queries and Rectified Attention field)の提案。
- 密なクエリをサポートするdecoder。
- PED(Pedestrian End-to-end Decoder)の提案。
- クエリのノイズや狭いattention fieldを緩和するdecoder。
- V-Matchの提案。
- 可視化されたアノテーションを十分に活用することで、さらなる性能向上を実現。
Lane Detection(レーン検出)
PolyLaneNetをベースにLiuらはLSTRを提案。
- Transformerネットワークを用いてグローバルコンテキストを学習することで、カーブの車線検出のパフォーマンスを向上。
- PolyLaneNetと同様に、レーンの検出を多項式でフィッティングするタスクとみなし、多項式のパラメータを予測するためにNNを使用。
- レーンの細長い構造とグローバルコンテキストの構造を捉えるために、LSTRは、transformer networkを導入。(CNNで抽出した低レベルの特徴を処理することができる。)
- Hungarian lossを用いてネットワークのパラメータを最適化する。
- PolyLaneNetの精度を2.82%上回り、5倍少ないパラメータで3.65倍のFPSを実現した。
4.2.3 Segmentation
DETRは、decoderにマスクヘッドを追加することでpanoptic segmentation (*画像上の全ピクセルをクラスに分類するのがsemantic segmentation, 物体ごとの領域を分割し、かつ物体の種類を認識するのがinstance segmentation, それらを組み合わせたのが、panoptic segmentation)タスク用に自然に拡張でき、競争力のある結果を得る。
Max-DeepLab: Wangらが提案。box検出などの代理のサブタスクを通さずにpanoptic segmentationの結果を直接予測。
- DETRと同様に、panoptic segmentationタスクをend-to-endで合理化し、重複しないマスクと対応するラベルのセットを直接予測する。
- モデルの学習は、panoptic quality(PQ) style lossを用いて行われる。
- CNN backboneの上にtransformerを重ねる先行手法とは異なり、CNNとtransformerの組み合わせを容易にするdual-path フレームワークを採用。
VisTR: Wangらが提案。transformer baseのvideo instance segmentation model.
- 予測結果に正解を当てはめるために、instance sequenceをマッチングする戦略が提案。
- 各instanceのマスクシーケンスを得るためにinstance sequence segmentation moduleを利用し、複数のフレームからマスク特徴を蓄積し、3D CNNでマスクシーケンスをセグメント化する。
Cell-DETR: DETR panoptic segmentation modelに基づき、cell(細胞) instance segmentationにtransformerを使用する試み。
- 特徴融合を強化するために、segmentation headのbackbone CNNとCNN decoderの間に特徴を橋渡しするskip 接続を追加する。
- 顕微鏡画像からのcell instance segmentation においてSOTA.
transformer-based semantic segmentation network(SETR): Zhengらが提案。
- ViTと同様のencoderを入力画像から特徴を抽出するencoderとして利用する。
- ピクセル単位のsegmentationを行うために、マルチレベルの特徴集約moduleを採用。
点群学習のためのtransformer利用も増えている。
- Guoら: オリジナルのself-attention moduleを陰解法ラプラス演算子と正規化改良を含む、より適切なoffset-attention moduleに置き換える新しいフレームワークを提案。
- Zhaoら: Point Transformerという新しいTransformer アーキテクチャを設計。point setの順列に対して不変であるため、ポイントセット処理タスクに適している。3D点群からのsemantic segmentation taskに対して強力な性能を発揮。
4.2.4 Pose Estimation
人間の姿勢の大域的な構造情報をモデル化するために、Transformerをどのように利用するかを検討したいくつかの手法を紹介。
Huangら: point setからの3D hand pose推定のためのtransformer baseのネットワークを提案。
- PointNetを利用して、入力点群から点ごとの特徴を抽出。
- 標準的な multi-head self-attention moduleを使用し、埋め込みを生成する。
- よりグローバルな姿勢関連情報をdecoderに出すために、PointNet++ などの特徴抽出器を用いて、手の関節ごとの特徴を抽出し、これを位置エンコーディングとしてdecoderに供給する。
同様にHuangらは、3D hand object の姿勢推定のためにHOT-Net(hand-object transformer network)を提案。
- ResNetを用いて、手の2次元物体の初期poseを生成し、それをtransformerに供給して手の3次元物体のposeを予測する。
- encoder用の入力埋め込みにspectral graph convoluitionを使用。
Linらは、1枚のRGB画像から3次元の人間の姿勢とメッシュを予測するmesh transformer(METRO)を提案。
- CNNを介して画像の特徴を抽出し、templateとなる人間のメッシュを画像特徴に連結することで位置のencodeを行う。
- 埋め込み次元を徐々に減らして、最終的に関節やメッシュの頂点の3D座標を生成するためにprogressive次元削減を用いたmulti-layer transformer encoder を提案。
- 人間の関節間の非局所的な関係の学習を促すために、学習時にいくつかの入力クエリをランダムにマスクする。
4.2.5 Discussions
- transformerは、detection, sementation, pose 推定などいくつかの高レベルのタスクで高い性能を示した。
- transformerを高レベルのタスクに採用するには、入力の埋め込み、位置の符号化、予測損失に関する重要な問題を解決する必要がある。
- deformable attention, adaptive clustering, point transfomer高レベルのCVタスクのためのtransformerの使用の研究は、まだ予備段階で、さらなる研究の余地あり。
- CNN, PointNetなどの特徴抽出モジュールをtransformerの前に使用する必要があるのか。
- NLP分野のBERT,GPT-3のように、大規模な事前学習データを使ってVision Transformerを十分に活用するにはどうすればよいか。
- 単一のtransformer modelを事前学習し、数エポックのfine-tuningで異なる下流タスクに対応することが可能なのか。
4.3 Low-level Vision
transfomerを画像の高解像度化、生成などいくつかのlow-levelのタスクに適用する研究は殆どない。これらは、high-levelのタスクよりも困難である。
Image Transformer:Parmar らが提案。画像の変換、生成タスクを定式化するためのtransfomerモデルの一般化に取り組んだ。
Image Transformerは2つの部分に分かれる。
- Encoder:画像表現を抽出
- 0~255の値を持つ各画素に対して、各値をd次元のベクトルにencodeするための256xd次元の埋め込みを学習し、これを入力とする。
- Decoder:ピクセル(画素)を生成
EncoderとDecoderはのAttention is all you needとものと同じ構造をしている。以下のFig8は、Decoderの各層の構造を示している。
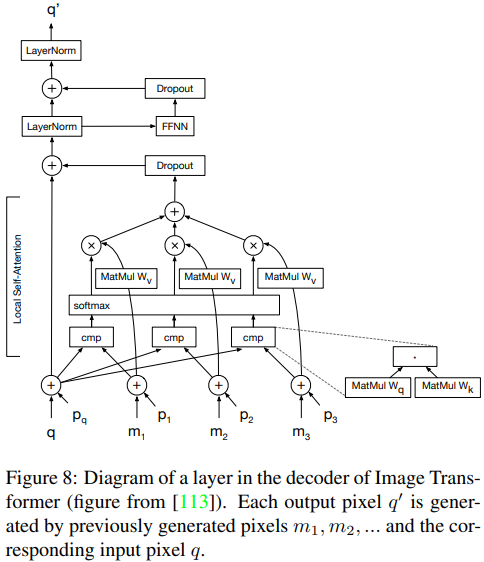
- 各出力画素q’は、入力画素qと、位置埋め込み$p_1, p_2, …$以前に生成された画素$m_1, m_2, …$とのself-attentionの計算によって生成される。
- 超解像やinpainting等、画像を条件にした生成には、encoder-decoderの構造が使用され、encoderの入力は、低解像または破損した画像。
- ノイズから画像への生成では、decoderのみがノイズベクトルの入力に使用される。
- decoderの入力は、過去に生成された画素であるため(高解像度の画像を生成するには高い計算コストがかかる)、local self-attentionが提案される。
この手法によってImage Transformerは画像生成及び翻訳タクスにおいてCNNベースのモデルと同等の性能を達成。low-levelの視覚タスクのTransformerの有効性を示した。
最近の研究では、transformerの入力として、各画素を使用することを避け、代わりにパッチ(画素の集合)を入力として使用するものが多くある。
Texture Transformer Network for Image Super-Resolution(TTSR): Yangらが提案。参照ベースの画像超解像問題において、transformer構造を用いる。
- 関連するテクスチャを参照画像から低解像度画像に転送することを目的としている。
- 低解像度画像と参照画像をそれぞれquery Q, key Kとすると、Qの各パッチ$q_i$とKの各パッチ$k_i$の間の関連性$r_{i,j}$は式12のようになる。
- $r_{i, j} = \langle \frac{q_i}{\| q_i \|}, \frac{k_i}{\| k_i \|}\rangle (12)$
- hard-attention moduleは、参照画像に応じて高解像度の特徴量Vを選択し、関連性を利用して低解像度の画像をマッチングできるようにする。計算は以下の通り。
- $\newcommand{\argmax}{\mathop{\rm arg~max}\limits}h_i = \argmax_j r_{i,j} (13)$
- 最も関連性の高い参照パッチは、$t_i = v_{h_i}$であり、Tの$t_i$は転送された特徴である。
- soft-attention moduleを使って、Vを低解像度の特徴Fに転送する。soft-attention は次のように計算される。
- $\newcommand{\max}{\mathop{\rm max}\limits}s_i = \max_j r_{i,j} (14)$
- 高解像度のテクスチャ画像を低解像度の画像に転送する式は次のように定式化できる。
- $F_{out} = F + Conv(Concat(F,T))\odot S. (15)$
- ここで$F_{out}$と$F$はそれぞれ低解像度画像の出力特徴と入力特徴、Sはsoft-attention, Tは高解像テクスチャ画像から転送された特徴である。
- $F_{out} = F + Conv(Concat(F,T))\odot S. (15)$
- transformer baseの構造を活用することで、超解像タスクにおいて、高解像度の参照画像から低解像度の画像へのテクスチャ情報の転送を成功させることができる。
Image Processing Transformer (IPT): Chenらが提案。単一のタスクに対してtransformer modelを利用する先行手法と異なり、大規模な事前学習データセットを使用することで、transformer modelの利点を十分に活用する。
- 超解像、ノイズ除去、deraining(*画像から雨、霧などを除去するタスク)などの画像処理タスクにおいて、SOTA。
- fig9のように、複数のヘッド、encoder, decoder, 複数のテールから構成されている。
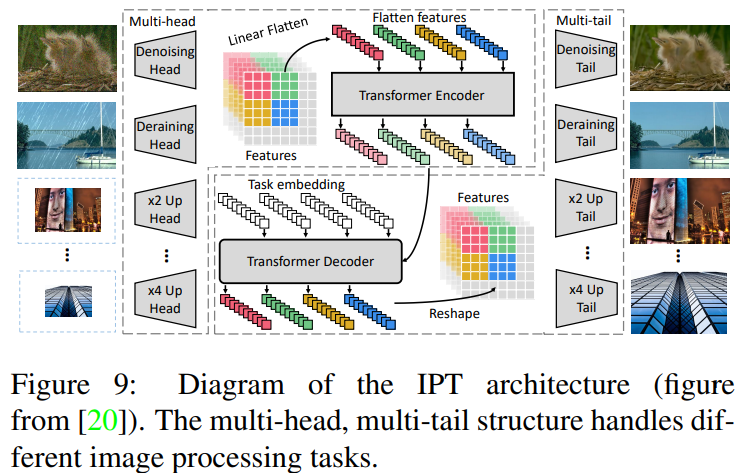
- 特徴量は、パッチに分割され、encoder, decoderの構造に入力される。
- 出力は、同じサイズに再形成される。
- ImageNetデータセットを事前学習に使用。
- ノイズや雨の筋を手動で加えたり、downsamplingを行ったりして劣化させ、破損した画像を生成する。
- 劣化した画像は、入力として使用され、元の画像は、出力の最適化目標として使用される。
- IPTモデルの一般化能力を高めるために、自己教師法が導入されている。
- モデルが学習されると、対応するヘッド、テール、及びタスクの埋め込みを使用して、各タスクで微調整される。
SceneFormer: Wangらが提案。単一の画像生成に加えて、3D屋内シーンの生成にtransformerを利用。
- シーンをオブジェクトのシーケンスとして扱うことで、transformer decoderを用いてオブジェクトのシーケンスとその位置、カテゴリ、サイズを予測することができる。
- 従来のCNNの手法を上回る結果を得る。
結論として、分類・検出タスクと異なり、画像生成・処理のoutputは画像である。fig10は、low-level visionにおけるtransformerの利用を示している。
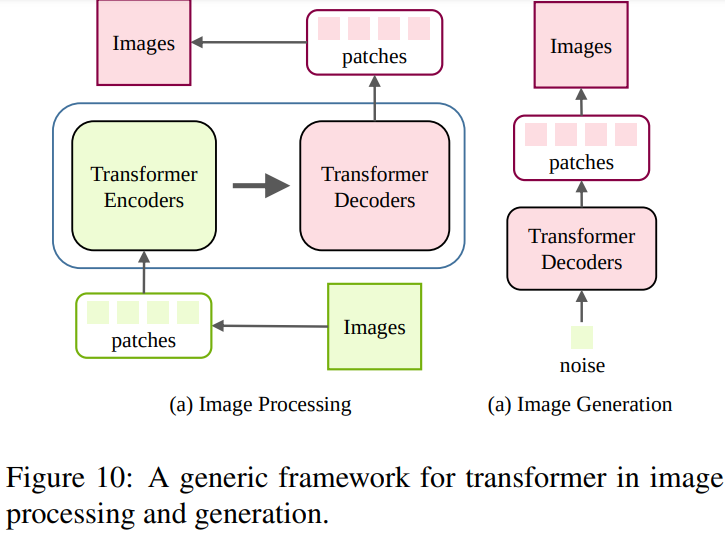
- 画像をピクセル、もしくはパッチのシーケンスとして捉え、transformer encoderがそのシーケンスを入力として利用することで、transformer decoderが目的の画像をうまく生成する事ができる。
- 今後の研究の方向性としては、様々な画像処理タスクに適した構造を設計することがあげられる。
4.4. Video Processing
CVの動画タスクでは、空間的、時間的次元情報が好まれている。フレーム合成、行動認識、動画検索など、多くの動画タスクにtransformerが適用されている。
4.4.1. High-level Video Processing
Image Generation
自然の画像データセットから画像を生成する。並列化可能な構造は、ピクセルブロックの予測を効率的に行うことができるので魅力的。
Parmarらは、尤度生成モデルに基づいて、transformerを用いて画像を生成した。local-attention moduleは、連続するピクセルブロックを予測するためにvision transformerに組み込まれている。
Activity Recognition
活動認識は、グループ内の人間の活動を識別することを含む。
- 従来手法は、個々のアクターの位置情報に基づいていた。
- Gavrilyukらは、2D,3Dネットワークによって生成された静的及び動的な表現を入力として表現を学習するためのactor-transformerを提案。
- transformerの出力は、予測されたactivity
Human Action Recognition
動画内の人間の行動を識別し、位置を特定することを含む。人間の行動を識別するには、コンテキスト(他の人や物体)が重要な役割を果たす。
- Rohitらは、対象となる人間と周囲のコンテキストとの間の基本的な関係をモデル化するために、Action transformerを提案。
- I3Dをbackboneにして、高レベルの特徴マップを抽出する。
- 中間特徴マップから抽出した特徴(RoI pooling等を使用)をクエリ(Q)とみなし、キー(K)と値(V)を中間特徴から計算する。
- 3つのコンポーネントには、self-attentionメカニズムが適用され、分類予測、回帰予測を出力する。
- Lohitらは、クラス内分散を小さくし、クラス間分散を大きくするためにtemporal transformer networkと呼ばれる解釈可能な微分モジュールを提案。
- FayyazとGallは、弱教師付きの設定下で、行動認識タスクを実現するためにtemporal transformerを提案。
Face Alignment
顔のランドマークをローカライズすることが目的。時間情報と、空間情報に大きくパフォーマンスに影響する。従来手法の課題は、連続するフレーム間の時間的情報と、静止フレーム上の補完的な空間情報の両方を捉えることができないこと。
- Liuらは、時間的特徴と、空間的特徴を別々に学習するtwo-stream transformer networksを提案。
- end-to-endで2つのstreamを共同で最適化し、最終的な予測値を得るために特徴を重み付けする。
Video Retrieval
コンテンツベースの動画検索の鍵となるのは、動画間の類似性を見つけること。
- Shaoらは、動画レベルの特徴のうち、画像レベルの特徴のみを活用し、長距離の意味的依存関係をモデル化するためにtransformerを利用することを提案。
- ハードネガティブマイニングを行うためにsupervised contrastive learning戦略を用いる。(*constrastive learning(CL)は、似ているデータは、潜在空間でも似た埋め込みベクトルになり、異なるデータは、潜在空間でも異なる埋め込みベクトルになるように学習する手法。supervised CLは、この手法を正解ラベルを用いてい行う。)
- 性能と速度の優位性が実証された。
- Gabeurらは、動画表現のために異なるcross-modalな手がかりを学習するmulti-modal transformerを提案。
Video Object Detection
動画中の物体を検出するためには、グローバルな情報と、ローカルな情報の両方が必要である。
- Chenらは、より多くのコンテンツを取り込むためにMemory Enhanced Global-Local Aggregation(MEGA)を導入。
- 全体的なパフォーマンスを向上させた。
- Yinらは、空間情報と時空間情報を集約するspatiotemporal transformerを提案。
- 別の空間特徴encodingコンポーネントと合わせて、これら2つのコンポーネントは、3D動画のobject detection taskで優れた性能を発揮。
Multi-task Learning
トリミングされていない動画には、通常、対象のタスクに関係ないフレームが多く含まれる。関連情報を抽出し、冗長な情報を破棄することが重要。
- Seongらは、video multi-task transformer networkを提案。
- トリミングされていない動画のマルチタスク学習を行う。
- CoVieW datasetでは、シーン認識、行動認識、重要度スコア予測がタスクになっている。
- ImageNetとPlaces364上で事前に学習された2つのネットワークが、シーン特徴と物体特徴を抽出する。
- multi-task transformerを重ねて、クラス変換行列(CCM)を利用した特徴融合を行う。
4.4.2. Low-levelll Video Processing
Frame/Video Synthesis
フレーム合成タスクは、連続した2つのフレームの間、あるいはフレームシーケンスの後のフレームを合成するもの。動画合成タスクは、動画を合成するものである。
- Liuらは、ConvTransformerを提案。
- 特徴の埋め込み、位置の符号化、encoder, queryのdecoder、合成フィードフォワードネットワークの5つのコンポーネントで構成されている。
- LSTM baseの手法と比べて、並列化可能な構造で、優れた結果を達成している。
- Schatzらは、transformer baseの別のアプローチを提案
- recurrent transformer networkを用いて、新しいviewから人間のアクションを合成するものである。
Video Inpainting
フレーム内の欠落した領域を保管するタスク。空間的及び時間的な次元に沿った情報を統合する必要があるため、困難である。
- Zengらは、spatialtemporal transformer networkを提案。
- すべての入力フレムを入力として使用し、それらを並行して埋める。
- このtransformer networkを最適化するためにspatialtemporal adversarial lossを用いる。
4.5. Self-attention for Computer Vision
このセクションでは、CVの困難なタスクのために設計されたself-attentionに基づくモデルを深く掘り下げる。
4.5.1.でself-attentionのアルゴリズムを定式化し、4.5.2.でself-attentionを用いたCVの既存のアプローチをまとめる。
4.5.1. General Formulation of Self-attention
機械翻訳のself-attention moduleは、埋め込み空間での重み付けに基づいて、すべての位置に注意をはらい、それに応じてそれらを合計することによって、シーケンス内の1つの位置での応答を計算する。これは、CVに適用できるnon-local filtering 操作のいち形態とみなすことができる。
- ここでは、参考文献を参考にして、self-attention moduleを構成する。
- 入力信号: $X \in \mathbb{R}^{n \times c}$
- $n= h\times w$(特徴量のピクセル数)
- c: チャネル数
- 出力信号: $y_i = \frac{1}{C(x_i)}\sum_{\forall j} f(x_i, x_j)g(x_j), (16)$
- $x_i \in \mathbb{R}^{1 \times c}$: 入力信号Xのi番目の位置(例えば、空間、時間、時空)
- $y_i \in \mathbb{R}^{1 \times c} (16)$: 入力信号Yのi番目の位置(例えば、空間、時間、時空)
- 添字j: すべての位置を列挙するインデックス
- 関数f(.): iとすべてのjの間の表現関係(親和性など)を計算
- 関数g(.): 位置jにおける入力信号の表現を計算。
- 係数$C(x_i)$: g(.)の応答を正規化
- 関数f(.)は、多くの選択肢があり、例えばガウス関数を単純に拡張して、埋め込み空間での類似度を計算する事ができる。定式化すると以下のようになる。
- $f(x_i, x_j) = e^{\theta (x_i) \phi (x_j)^T} (17)$
- $\theta(.), \phi(.)$: 任意の埋め込み層
- $\theta(.), \phi(.), g(.)$を線形埋め込みの形で考えると: $\theta (X) = XW_{\theta}, \phi (X) = XW_{\phi}, g(X) = XW_g$
- $W_{\theta} \in \mathbb{R}^{c \times d_k}, W_{\phi} \in \mathbb{R}^{c \times d_k},W_{g} \in \mathbb{R}^{c \times d_k}$とし、正規化係数を$C(x_i) = \sum_{\forall j}f(x_i, x_j)$とすると、式16は、次のように書き換えられる。
- $y_i = \frac{e^{x_i w_{\theta, i}w^T_{\phi, j}x^T_j}}{\sum_j e^{x_iw_{\theta, i}w^T_{\phi, j}x^T_j}}x_jw_{g,j}, (18)$
- $W_{\theta, i} \in \mathbb{R}^{c \times d_k}$は、重み行列$W_{\theta}$のi番目の行。
- 与えられたindex iに対して、$\frac{1}{C(x_i)}f(x_i, x_j)$は、次元jに沿ったsoftmax 出力となる。
- この定式化は更に次のように書き換えられる。
- $Y = softmax(XW_{\theta}W^T_{\phi}X)g(X), (19)$
- $Y \in \mathbb{R}^{n \times c}$はXと同じサイズの出力信号
- 翻訳モジュールからのquery, key, valueの表現$Q = XW_q, K = XW_k, V = XW_v$と比較して、$W_q = W_{\theta}, W_k = W_{\phi}, W_v = W_g$となると、式19は次のように定式化できる。
- $Y = softmax(QK^T) V = Attention(Q, K, V), (20)$
- 機械翻訳のために提案されたself-atteniton moduleはある程度CVのために提案された先行するnon-local filtering 操作と同じである。
- 一般的にCV用のself-attention moduleの最終出力信号は次のように表現される。
- $Z = YW_Z + X (21)$
- Y: 式19で生成される
- $W_Z$がゼロとして初期化されている場合、このself-attention moduleは、その初期化の動作を壊すことなく、任意の既存のモデルに挿入することができる。
- $f(x_i, x_j) = e^{\theta (x_i) \phi (x_j)^T} (17)$
4.5.2. Applications on Visual Tasks
self-attention moduleは、大きな受容野に関するスケーリング特性が低いCNNアーキテクチャのブロックで構築されていると考えられる。この構成要素は、長距離の相互作用を補足し、CVのための高レベルの意味的特徴を強化するために使用される。以下では、画像分類、セマンティックセグメンテーション、物体検出などの画像ベースのタスクのために、self-attentionに基づいて、提案された手法を紹介する。
- Image Classification
- 分類のためにattentionを使用するにあたって、主に2つの手法の流れがある。
- hard attention
- 画像領域の使用に関係する
- Beらは、画像分類タスクにvisual attentionという用語を最初に提案。
- soft attention
- 非剛体の特徴マップを生成する。
- Jetleyらは、対応する推定機によって生成されたattention mapを用いて、DNNの中間特徴を再重み付けする。
- Hanらは、CNNの表現力を高めるために、属性を考慮したattentionを利用した。
- Semantic Segmentation
- PSANet, OCNet, DANet, CFNetはセマンティックセグメンテーションタスクにself-attention moduleを使用することを提案した先駆的な作品。
- 文脈上のピクセル間の関係性や類似性を考慮し、強化している。
- DANet: 空間的な次元とチャネルの次元でself-atteniton moduleを同時に活用。
- A2Net: ピクセルを一連の領域にグループ化し、生成された注意重みで領域表現を集約することで、ピクセル表現を増強している。
- DGCNet: dual graph CNNを採用し、座標空間の類似性と特徴空間の類似性を単一のフレームワークでモデル化。
- self-attention moduleの効率を向上させるために、ピクセルの類似性を計算することによってもたらされる膨大な量のパラメータを軽減することを目的とした提案手法もある。
- CGNL: RBFカーネル関数のテイラー級数を用いて、ピクセルの類似性を見つける。
- CCNet: 2つの連続した十字型の注目モジュールによって、オリジナルのself-attention方式を近似している。
- ISSA: 密な親和性行列を2つの疎な親和性行列の積として因数分解知ている。
- attentionに基づくグラフ推論モジュールを用いて、局所的および大域的な表現を強化する関連研究が他にもある。
- Object Detection
- Ramachandranらは、attention baseの層を交換して、完全にattention型の検出器を構築し、COCOベンチマークにおいて典型的なRetinaNetを凌駕している。
- GCNetは非局所的な演算によってモデル化されたグローバルコンテキストが、画像内の異なるクエリ位置でもほぼ同じであることを仮定し、簡略化された定式化とSENetをグローバルコンテキストモデリングのための一般的なフレームワークに統合している。
- Voらは、クエリ位置から可能なすべての位置に情報を収集して配布するための双方向の操作を設計。
- Zhangらは、従来の手法では、スケールを超えた特徴との相互作用に失敗していることを指摘し、空間とスケールの両方を超えた相互作用を完全に利用するために、self-attentionモジュールに基づいたFeature Pyramid Transformerを提案
- Huらは、self-attentionに基づく関係モジュールを提案。一連の外観特徴間の相互作用を通じて、同時にオブジェクトを処理する。
- Chengらは、self-attentionと同様に異なる異種の表現を単一の表現に統合するために、BVR(Bridgeing visual Representations)モジュールを備えたRelationNet++を提案。
- マスター表現をクエリ入力とし、補助的な情報をキー入力とする。
- Other Vision Tasks
- Zhangらは、multi-resolution networksを学習する際に、強化された特徴マップを学習するための解像度別のattention moduleを提案。pose推定のための正確な人間のキーポイント位置を得た。
- Changらは、attention メカニズムに基づく特徴融合ブロックを用いて、人間のキーポイント検出モデルの精度を向上させている。
- Johnstonらは、自己教師付き単眼学習深度推定を改善するために、より一般的なコンテキスト情報を探索するために、self-attention moduleを直接利用。
- Chenらは、奥行き推定のために多様なシーンで異なるコンテキスト情報を取り込むためにattentionに基づく集約ネットワークを提案。
- Aichらは、単眼深度推定の結果を向上させるために、前方及び、後方へのattnetion操作を利用する双方向attnetion moduleを提案。
4.6. Efficient Transformer
transformer modelは、様々な分野で成功を収めているが、メモリや計算機資源への要求が高く、携帯電話などの資源が限られた機器への実装を阻んでいる。このセクションでは、効率的な実装のためのtransformerモデルの圧縮および高速化に関する研究を紹介する。表5に代表的な手法をまとめた。
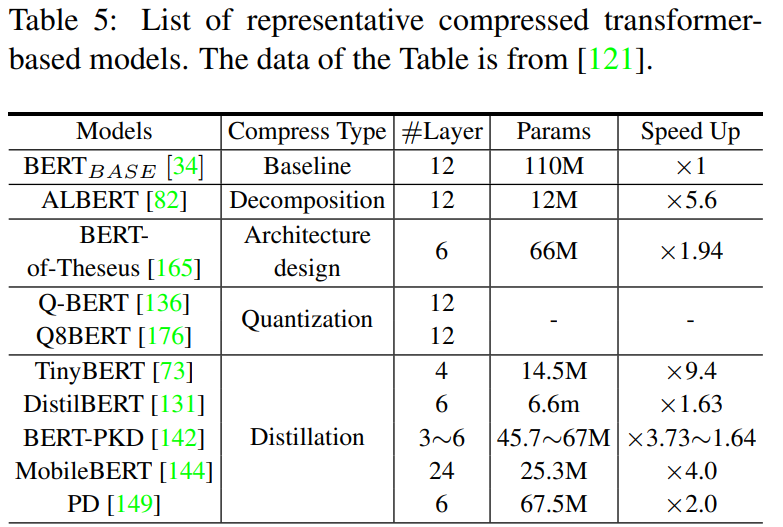
4.6.1. Pruning and Decomposition
attentionに基づく事前学習モデル(例:BERT)では、異なるトークン間の関係を独立してモデル化するために、複数のattention操作が並行して実行される。しかし特定のタスクでは、すべてのヘッドを使用する必要はない。
- Michelらは、テスト時に大部分のattention headを削除しても性能に大きな影響を与えないという経験的な証拠を提示している。
- 必要なheadの数は、レイヤーごとに異なり、中員は1つのheadしか必要としないレイヤーもある。
- atetention headの冗長性を考慮して重要度スコアを定義し、各ヘッドが最終出力に与える影響を推定している。
- Dalviらは、学習済みの変換モデルにおける冗長性を一般的な冗長性とタスク固有の冗長性という2つの観点から分析した。
- Prasannaらは、宝くじ仮説に従い、BERTの宝くじを分析し、高圧縮性を達成するためにFFN層とattention headの両方を削減して良好なサブネットワークもtransformer baseのモデルに存在することを示した。
- transformer modelの幅に加えて、深さ(すなわち層の数)も推論プロセスを加速するために減らすことができる。
- Fanらは、モデルの学習を正規化するために、層ごとにドロップする戦略を提案し、テスト段階では、層全体をまとめて削除する。
- Houらは、デバイスごとに利用可能なリソースが異なることを考慮して、予め定義されたtransformerモデルの幅と深さを適応的に縮小することを提案。
- サイズの異なる複数のモデルを同時に取得し、重要なattention headやニューロンを再配線メカニズムによって異なるサブネットワーク間で共有している。
- Wangらは、transformer modelにおける標準的な行列の乗算を分解し、推論の効率を向上させている。
4.6.2. Knowledge Distillation
知識の蒸留は、大規模な教師ネットワークから知識を転移して生徒ネットワークを訓練することを目的としている。教師用ネットワークと比較して、生徒用ネットワークは、通常薄くて浅い構造なので、限られたリソースに展開するのが容易である。
- Mukherjeeらは、事前に学習したBERTを教師として使用し、大量のラベルなしデータを活用して小型モデルの学習を行った。
- Wangらは、事前に学習した教師モデルのself-attention層の出力を模倣するように生徒ネットワークを学習。生徒ネットワークのために値の間のdot積が新しい知識として導入。
- 教師のアシスタントを導入。事前に学習された大規模なtransformer modelとコンパクトな学生ネットワークとの間のギャップを減らすことで模倣作業を容易にしている。
- transformer modelには様々な種類の層があるので、Jiaoらは、教師から学生に知識を伝達するための異なる目的関数を設計。
- 学生モデルの埋め込み層の出力は、MSE損失によって教師の出力を模倣。
- 異なる特徴を同じ空間にマッピングするために、学習可能な線形変換を使用。
- 予測層の出力には、異なるモデル間のあを測定するためにKL-divergenceを採用。
4.6.3. Quantization
量子化は、ネットワークの重みや中間特徴を表すのに必要なビット数を減らすことを目的としている。多くの手法が提案され、最近では、transformer modelを量子化する方法への関心が集まっている。
- Shridharらは、入力を2値の高次元ベクトルに埋め込み、その2値の入力表現を用いて、2値のNNを学習することを提案している。
- Cheongらは、transformer modelの重みを低ビット(例えば4bit)で表現している。
- Zhaoらは、様々な量子化手法を経験的に調査し、k-means 量子化に大きな発展性があることを示した。
- Pratoらは、機械翻訳タスクを目的として、完全に量子化されたtransformerを提案。(翻訳品質が低下しない初めての8bitモデルであると主張)
4.6.4. Compact Architecture
定義済みのtransformer modelをより小さなモデルに圧縮するだけでなく、コンパクトなモデルを直接設計しようとする研究もある。
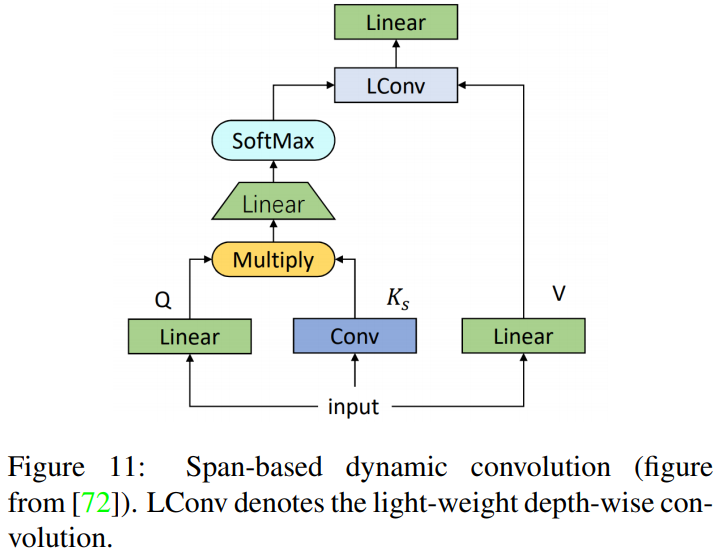
- Jiangらは、fig11に示すように、全結合層と畳恋層を組み合わせたspan-based dynamic convolutionと呼ばれる新しいモジュールを提案することで、self-attentionの計算を簡素化。
- 異なるトークンからの表現間の局所的な依存性は、畳込み演算によって計算される。これは、標準的なtransformerの高密度な全結合層よりも遥かに効率的。
- 深さ方向の畳込みを行うことで、更に計算コストを削減することができる。
- 行列分解を用いてオリジナルのself-attention 層を置き換えるhamburger 層の提案。行列分解は、標準的なself-attneiton 演算と比較して異なるトークン間の依存性を明確に反映しながら、より効率的に計算することができる。
- Katharopoulosらは、self-attention をカーネル特徴マップの線形ドット席として近似し、RNNを介してトークン間の関係を明らかにした。
- Zaheerらは、各トークンをグラフの頂点とみなし、2つのトークン間の内積計算をエッジと定義。グラフ理論にヒントを得て、様々なスパースグラフを組み合わせて、transformer modelの密なグラフを近似。
- Yunらは、計算複雑性O(N)のスパースなtransformerは、トークン間のあらゆる種類の関係を反映するのに十分であり、普遍的な近似を行うことができることを証明。
考察
先に述べた方法は、transformer modelの冗長性をどのように特定しようとしているかについて、異なるアプローチを取っている。(fig12参照)
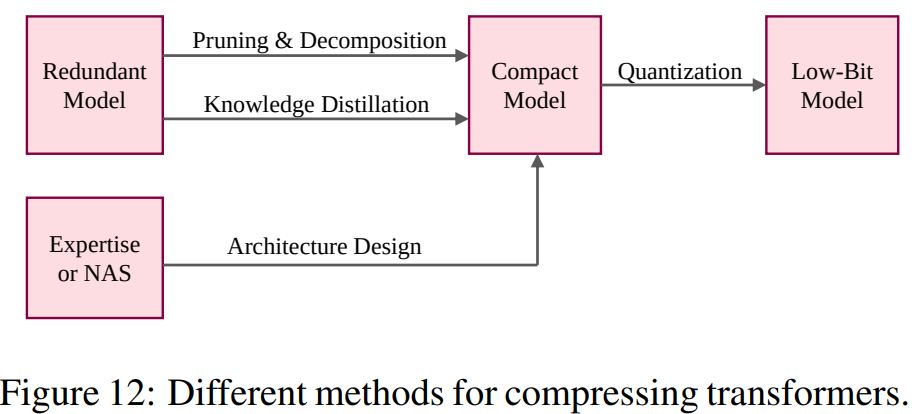
- 刈り込み:transformer modelのコンポーネント(レイヤーやヘッド)の数を減らすことに焦点。
- 分解:もとの行列を複数の小さな行列で表現
- コンパクトモデル:手動もしくは自動(NASなど)で直接設計。
- 量子化:コンパクトモデルを低ビットで表現し、限られたリソースに導入。
5. Conclusions and Discussions
Transformerは、CNNと比較して競争力のある性能と多大な可能性を持っているため、CVの分野でホットな話題になっている。様々な手法が提案されているが、transformerの可能性は未だ完全に追求されておらずいくつかの課題を解決する必要がある。このセクションでは、これらの課題を議論し、将来の展望についての考察を述べる。
5.1. Challenges
- ViTのtransformer構造は、NLPの標準的なtransformerを踏襲しているが、CVに特化した改良版の検討が必要。
- 前述したタスク以外にもより多くのタスクにtransformerを適用する必要がある。
- transformerの一般化とロバスト性
- 純粋なtransformerにはいくつかの帰納的バイアスがなく、大規模な訓練のために膨大なデータセットに大きく依存している。
- ViTはCIFARやVTABなどの下流の画像分類タスクで卓越した性能を示したが、物体検出にViTのbackboneを直接適用してもCNNよりも良い結果を得ることはできなかった。
- なぜtransformerが視覚タスクでうまく機能するのかを明確に説明することは困難。
- CNNの成功の原因は、翻訳の等変性や、局所性などの帰納的バイアスにあるが、transformerには帰納的バイアスがない。
- 現在の研究では、通常この効果を直感的に分析している。Dosoviskiyらは、大規模な訓練が、帰納的バイアスを超えられると主張している。
- 位置埋め込みは、CVのタスクで重要な位置情報を保持するために、画像パッチに追加される。transformerにおけるパラメータの多用にヒントを得て、オーバーパラメータ化は、visual transformerの解釈可能性に対する潜在的なポイントかも知れない。
- transformer modelは通常、巨大で計算コストがかかる。
- baseとなるViTモデルでは、1つの画像を処理するのに180億FLOPsを必要とする。
- 軽量のCNNモデルであるChostNetでは、約6億FLOPsで同様の性能を達成できる。
- NLPように設計されているので、CVに適した効率的なtransformerモデルの提案が急務
5.2. Future Prospects
visual transformerの将来の展望についていくつかの潜在的な方向性を示す。
- CVにおけるtransformerの有効性と効率性。
- 目標:効果的かつ効率的なvisual transformerの開発。
- 高性能かつ低リソースコストのtransformer。
- 性能はモデルが実世界のアプリケーションに適用できるかどうかを決定。
- リソースコストは、デバイスへの展開に影響。
- 有効性は通常、効率性と相関関係にあるため、両者のバランスを取る方法は今後の研究の重要なテーマ。
- 高性能かつ低リソースコストのtransformer。
- 目標:効果的かつ効率的なvisual transformerの開発。
- すべての視覚タスク、更には他のタスクを1つのtransformerに統一すること
- 既存のvisual transformerモデルの多くは、単一のタスクのみを処理するように設計されている。
- GPT-3のような多くのNLPモデルは、transformerが1つのモデルで服ううのタスクをそりする方法を示している。
- CV分野のIPTは、超解像、画像のノイズ除去、ディレーニング等、複数の低レベルの視覚タスクを処理することができる。
- CNNとtransformerのどちらを使うか
- CNNは翻訳の等変性や、局所性などの帰納的なバイアスを捉えることができるが、ViTは大規模な学習により、帰納的なバイアスを凌駕する。
- 現在得られている証拠によると、CNNは小さなデータセットでよく機能し、transformerは大きなデータセットでよく機能する。
- NNに必要なのは、帰納的なバイアスではなく、ビッグデータである可能性がある。
- 大規模なデータセットで訓練することで、transformerはNLPとCVベンチマークの両方でSOTA。
- transformerは、非常に単順な計算パラダイム(例えば全結合層のみ)と大量のデータトレーニングで満足の行く結果を得ることができるのか。
*今回は最近話題のVisual transformerに関するsurvey論文を読みました。今度は最近(2021年3月現在)FAIRが発表した動画向けのtransformerモデルであるTimeSformerを読んでみたいと思います。