【論文読み】MoViNets: Mobile Video Networks for Efficient Video Recognition 日本語まとめ
CVPR2021, Google ReserchのDan Kondratyukさんらの論文
忙しい人向け
どんな論文か
- モバイルなどのデバイスでも利用しやすい効率的な動画分類モデルMoViNetsを提案。
先行研究と比べてどこがすごい
- Kinetics, Moments in Time , Charades video action recognition datasetでSOTAの精度と効率。
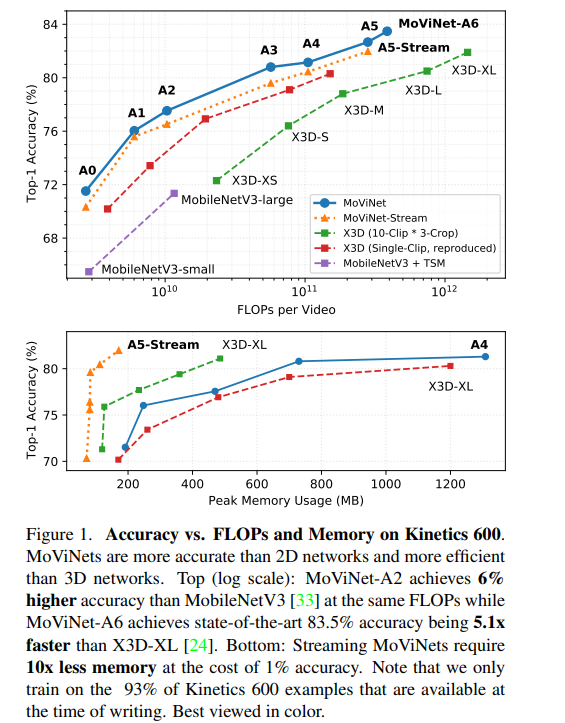
- 特にMoViNet-A5-Streamでは、Kinetics 600においてX3D-XLと同等の精度を達成する一方で、必要なFLOP数は80%、メモリは65%削減されている。
技術の手法やキモ
- 動画をオンラインで推論するとき、3DCNNは計算コストが高くて使えなかった。しかし、MoViNetsでは、3DCNNのピークメモリ使用量を大幅に削減しつつ、計算効率を向上させるための3つのステップを提案する。
- 動画ネットワーク検索空間を設計し、効率的で多様な3DCNN構造を生成する。
- メモリと動画クリップの長さを切り離すストリームバッファ技術を導入し、3DCNNが任意の長さのストリーミング動画シーケンスを学習と推論の両方に埋め込むことを可能にする。
- 効率を犠牲にすることなく精度を向上させるためにシンプルなアンサンブル技術を提案。
論文詳細
Introduction
効率的で精度の高い動画認識モデルが、mobile cameraやIoT, 自動運転アプリなどに向けて需要が高まっている。近年では、3D CNNモデルがSOTAを獲得しているが、リソースコストは高い。一方2DCNNは、リソースが少なく、オンラインで実行できるが精度が低い。
3D CNNを使ったモデルは、多くの演算が必要でモバイルに展開する機会が限られてしまう。最近のX3Dネットワークも大きなメモリリソースを必要とする。2D CNNを時間的集約を用いて精度向上させる研究もあるが、3D CNNほど長期的な時間依存性を適切にモデル化できない。
本手法では、メモリと計算量を節約できる3D CNNファミリーのMobile Video Networks(MoViNets)を生成する。
- 時間的特徴表現を効率的にトレードオフするために、Neural Architecture Search(NAS)を可能にするMoViNet探索空間を定義する。
- MoViNetsのためのストリームバッファを導入する。
- これにより、動画を小さな連続したサブクリップとして処理し、動画間の長期的な依存関係を損なうことなく一定のメモリで推論を可能にする。
- ストリームバッファによってわずかに失われた精度を取り戻すために、streaming MoVileNetsの時間的なアンサンブルを作成する。
生成されたMoViNetsの効率を視覚化したものを図1に示す。
Related Work
Efficient Video Modeling
- 二次元の画像モデルを時間的な次元で拡張する研究
- 3D CNNを取り入れた研究
- 動画をより小さなセグメントに分けて処理したあと、後半に結合を行うことで動画に2D networkを使用することを模索する研究
- 2DCNNのチャネルの一部を時間軸に沿ってシフトするTSM
Causal Modeling
- 因果的な畳込みを利用するWaveNet。一次元畳み込みのスタックの受容野は、現在の時間ステップまでの特徴にのみ拡張される。
Multi-Objective NAS
- NASと多目的アーキテクチャ探索との併用の研究
- 本研究ではOne-shot NAS フレームワークのTuNASを利用。
Efficient Ensenbles
- 最近の研究では画像分類において、小さなモデルのdeepアンサンブルは、単一の大きなモデルよりも効率的であることが示されている。本手法ではこれを動画分類に拡張。
Mobile Video Networks(MoViNets)
MoViNetsアプローチの3つのステップを示す。
Searching for MoViNet
2D mobile Network探索の実践に続き、TuNASフレームワークを使用する。これは、候補モデルのスーパーネットワーク上で重みを共有するワンショットNASのスケーラブルな実装であり、動画の3DCNNに再利用する。Kinetics600を使用してすべてのモデルを探索する。各モデルは25fpsで合計250frameの10sの動画シーケンスで構成されている。
MoViNet Search Space
探索空間の基本的な概要を表1に示す。

対象となるMoViNetsへの入力の寸法とフレームストライドをそれぞれ、$T \times S^2 = 50 \times 224^2 $そして$\tau=5(5fps)$で表す。
ネットワークの各ブロックについて、ベースとなるフィルタの幅$c^{base}$と、ブロック内で繰り返す層の数$L \leqq 10$を探索する。
各ブロックの特徴マップのチャンネルには、8の倍数に丸められた乗数{0.75, 1, 1.25}を適用した。n=5ブロックとし、第4ブロックを除く各ブロックの第1層には、空間分解能$7^2$を確保するために、strided空間ダウンサンプリングを行った。各ブロックには、特徴マップのチャンネルを徐々に増やしていく。{16, 24, 48, 96, 96, 192}最後の畳み込み層の基本フィルタ幅は512で、その後、分類層の前に2048Dの密な層が続く。
新しい時間次元を用いて、各層内の3Dカーネルサイズを$k^{time} \times (k^{space})^2 $と定義し、以下のいずれかを選択する。
{1x3x3, 1x5x5, 1x7x7, 5x1x1, 7x1x1, 3x3x3, 5x3x3}
これらの選択により、レイヤーは異なる次元の表現に焦点を当てて集約することができ、ネットワークの受容野を最も適切な方向に広げる一方で、他の次元のFLOPを削減することができる。カーネルサイズによっては、異なる数の入力フィルタを持つことが有益な場合があるので、ボトルネック幅cの範囲を探索し、$c^{base}$に対する{1.5, 2.0, 2.5, 3.0, 3.5, 4.0}の乗数として定義した。各レイヤーは、3D convを2つの1x1x1 convで囲み、$c^{base}$と$c{expand}$の間を拡張及び投影する。
フレーム単位の予測を可能にするために、時間的なダウンサンプリングは行わない。squeeze-and-excitation (SE)を適用する代わりにSEブロックを使用して3D 平均プーリングを介して時空間の特徴を集約し、すべてのボトルネックブロックに適用する。SEは探索可能で、FLOPsを節約するためにオプションで無効にすることができる。
Scalling the Search Space(探索空間の拡大)
我々の基本探索空間はMoViNet-A2の基礎を形成する。他のMoViNetsには、EfficientNetで使用されたものと同様の複合スケーリング・ヒューリスティックを適用している。我々のアプローチの大きな違いは、単一のモデルではなく、探索空間自体をスケーリングすること(すなわちmodel A0~A5の探索空間)。良いアーキテクチャを見つけてからそれをスケーリングするのではなく、すべてのアーキテクチャのすべてのスケーリングを探索し、可能なモデルの範囲を広げる。スケーリング係数(最初の目標はフレームあたり300MFLOPS)を見つけるために、小さなランダム探索を使用し、探索スペース内のサンプルモデルの予想サイズをおよそ2倍または半分にする。係数選択にあたっては、ベース解像度$S^2$フレームストライド$\tau$ブロックフィルター幅$c^{base}$そしてブロック深度Lを変更する。
異なるFLOPsターゲットで探索を行い、MObileNetV3のようなサイズからResNet3D-152のサイズまでのモデル群を作成した。
探索によって効率の良いネットワークファミリーを生み出せたが、MoViNetのメモリフットプリントは入力フレーム数に比例して増加するため、モバイル機器で長時間の動画を処理することは困難である。そこで次にストリーム・バッファを導入してネットワークのメモリ消費量を動画の長さに比例して一定になるように削減する。
The Stream Buffer with Causal Operations
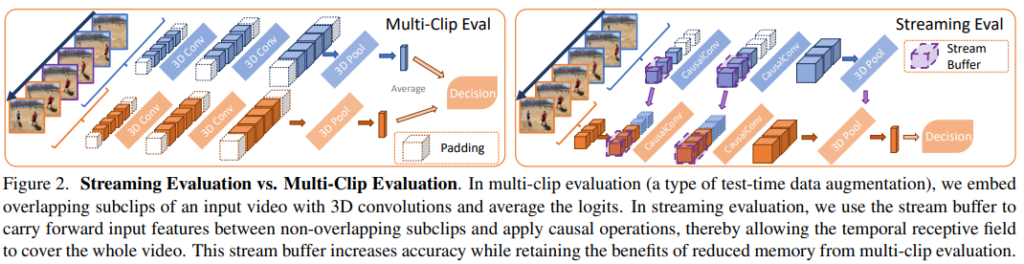
T フレームの動画xがあるとき、モデルが設定したメモリを超過する可能性がある。メモリを削減する一般的な方法として、fig2の左図のようにTクリップ<Tフレームとなるようなn個のオーバーラップするサブクリップ全体の予測値を平均化する。これによってメモリ消費量は0(T clip)に減少する。しかし、これには2つの大きな欠点がある。
- 時間的な需要屋が書くサブクリップに限定され、長距離の依存性が無視されるため、精度が低下する可能性がある。
- 重複するフレームの活性化を再計算するため、効率が落ちる。
Stream Buffer
これらの制限を超えるためにfig2の右図に示すように、サブクリップの境界上の特徴活性化をキャッシュするメカニズムとして、stream bufferを提案する。これによってサブクリップ間で時間的受容野を拡大することができ、再計算を必要としない。
形式的には、$x^{clip}_i$をステップ$i<n$における現在のサブクリップとし、ここでは動画をそれぞれ長さT clipのn個の隣接する重ならないサブクリップに分割する。時間次元の長さbを持ち、他の次元が$x^{clip}_i$と一致するバッファBをzero初期化したテンソルから始める。時間次元に沿ってサブクリップと連結($\oplus$)されたバッファの特徴マップ$F_i$を次のように計算する。
$\tag{1} F_i = f(B_i \oplus x^{clip}_i)$
fは時空間的演算を表している。(e.g. 3D convolution)次のクリップを処理する際には、バッファの内容を次のように更新する。
$\tag{2} B_{i+1} = (B_i \oplus x^{clip}_i)_{[-b:]}$
[-b:]を結合された入力の最後のb framesを選択したものとして定義する。結果としてメモリの消費量は$O(b+T^{clip})$に依存する。これは、動画の総フレーム数Tやサブクリップの数nが増加しても変わらない。
Relationship to TSM.
Temporal Shif Module(TSM)はstream bufferの特殊なケースと考えることができる。b=1でfはフレームtでの空間的な畳込みを計算する前にバファ内$B_t = x_{t-1}$のチャネルの割合を入力$x_t$にshiftさせる演算である。
Causal Operations
3D CNNの演算をstream bufferに適合させるための合理的なアプローチは、因果関係を強制すること。すなわち、いかなる特徴も将来のフレームから計算されてはいけないということである。これには、活性化や予測に影響を与えずにsubclip$x^{clip}_i$を1フレームに縮小することができるなど多くの利点があり、3D CNNがオンライン推論のためにストリーミング動画上で動作することを可能にしている。非因果的な操作、例えば時間的表方向のバッファリングを使用することは可能であるが、モバイルにとって望ましい特性であるオンラインモデリング機能を失うことになる。
Causal Convolution (CausalConv)
畳み込みの並進等変量特性を利用して、すべての時間的畳込みをCausalConvsに置き換え、効果的に時間的次元に沿って単方向にする。具体的にはまず、すべての軸にわたって畳み込みのバランスを取るためにパディングを計算し、最終フレーム後のパディングを移動させ、最初のフレームの前のパディングと統合する。
CausalConvでストリームバッファを使用する場合、因果関係のあるパディングをバッファ自体に置き換え、前のサブクリップから最後の数フレームを繰り越して次のサブクリップのパディングにコピーすることができる。時間的カーネルサイズがkとすると(strided samplingを使用しない)、パディング、つまりバッファの幅は$b=k-1$となる。通常k=3であることからb=2となり、結果的にメモリフットプリントが小さくなる。ストリームバッファが必要になるのは複数のフレームの特徴を集約するレイヤーの前田家なので、空間的及びポイント的な畳込み(1x1x1, 1x3x3など)はそのままにして、更にメモリを節約することができる。
CGAP(Cumulative Gloval Average Pooling)
CGAPを用いて時間次元を含むあらゆるグローバルな平均プーリングを近似する。frame $T’$までのすべての活性化について、これを累積和として計算することができる。
$\tag{3} CGAP(x, T’)= \frac{1}{T} \sum ^{T’}_{t=1}{x_t}$
xは活性化のtensorを表している。CGAPを因果的に計算するためにT’までの累積和を格納した1フレームのストリームバッファを保持しておく。
CausalSE with Positional Encoding
CGAPをSEに応用したものをCausalSEと定義し、フレームtの空間特徴マップとCGAP(x,t)から計算されたSEをかけ合わせる。実証実験の結果、CaousalSEは、映像の初期段階で分散が大きいCGAP推定値の品質をSE投影層が判断しづらいため、不安定になりやすいことがわかった。この問題を解決するために、Transomersにヒントを得て、制限はベースの固定位置符号化(POSENC)スキームを適用した。フレームインデックスを位置として直接使用し、SE投影を適用する前にCGAP出力とベクトルを合計する。
Training and inference with Stream Buffers Training
学習時に必要なメモリを削減するために、再帰学習戦略を使用する。例として与えられたバッチをn個のサブクリップに分割し、各サブクリップに対して予測を出力するフォワードパスを適用し、ストリームバッファを使用して活性化をキャッシュする。しかし、前のサブクリップのメモリが開放されるように、バッファを超えて勾配を誤差逆伝播することはしない。代わりに損失を計算し、サブクリップ間で計算された勾配を蓄積する。こればバッチ勾配蓄積と同様。これにより、ネットワークはすべての$T=nT^{clip}$フレームを考慮し、勾配を適用する前にn回のフォワードパスを実行する。この学習戦略により、ネットワークはより長期的な依存関係を学習することができ、動画の長さが短い場合に学習されたモデルよりも高い精度が得られる。Tクリップは、精度に影響を与えることなく、任意の値に設定することができる。しかし、GPUなどは、大きなテンソル計算をすることで有益となるので通常学習の際$T^{clip} \in {8, 16,32}$の値を設定する。これによりメモリコストを慎重にコントロールしながらトレーニングを加速することができる。
Online Inference
CausalConvやCausalSEのような因果関係のある演算を用いることの大きな利点は、3DビデオCNNをオンラインで動作させることができることである。訓練と同様に、サブクリップ間の活性化をキャッシュするためにストリーム・バッファを使用する。しかし、サブクリップの長さを1フレームに設定することで($T^{clip} = 1$)、メモリを最大限に節約することができる。これにより,フレーム間の遅延が減少し,モデルはストリーミングビデオ上でフレームごとに予測値を出力し,リカレントネットワーク(RNN)のように新しい情報を段階的に蓄積することができる.しかし、従来の畳み込みRNNとは異なり、ステップごとに可変のフレーム数を入力して、同じ出力を得ることができる。CausalConvを搭載したストリーミング・アーキテクチャでは、CGAPを用いてフレームごとの出力特徴をプールすることで、ビデオのラベルを予測する。
Temporal Ensembles
ストリームバッファは、Kinetics 600で約1%の精度低下を伴うものの、MoViNetsのメモリフットプリントを最大で1桁削減することができる。この精度を回復するために、単純なアンサンブル戦略を使用する。同じアーキテクチャで2つのMoViNetsを独立して訓練するが、フレームレートは半分にし、時間的な長さは同じにする(結果的に入力フレームは半分になる)。そして、Softmaxを適用する前に、重み付けされていないロジットに算術平均を適用する。この方法では、フレームレートを半分にする前の1つのモデルと同じFLOP数を持つ2つのモデルのアンサンブルが得られ、より豊かな表現による予測が可能になる。我々の観察では、アンサンブル内の両方のモデルが、個々のモデルよりも低い精度を持っている可能性があるにもかかわらず、アンサンブルされた場合には、単一のモデルよりも高い精度を持つことができる。
Experiments on Video Classification
MoViNetsの精度、効率、メモリ消費量を5つのaction recognition datasetを用いて評価する。
Datasets
- Kinetics
- 400
- 600
- 700
- Charades
- Moments in Time
- SomethingSomething V2
- Epic Kitchens 100
Implementation Details
- 各データセットで最初からRGBフレームを用いて学習
- すべてのデータセットで様々なフレームレートで64個のフレーム(推論フレームが少ない場合を除く)を用いて訓練し、同じフレームレートで推論。
- Kinetics600を用いてTuNASを実行し、FLOPsターゲットを持つ7つのMoViNetsをそれぞれ保持する。
- モデルが大きくなるにつれて、スケーリング係数はネットワークの入力解像度、フレーム数、深度、及び特徴幅を増加させる。
- 画像分類に用いられるAutoAugment増幅の実験も行った。
- 動画ごとにランダムな画像拡張をサンプリングし、各フレームに同じ拡張を適用。
Single-Clip vs. Multi-Clip
すべてのモデルを入力映像から一定のストライドでサンプリングされた1つのクリップで評価したところ、映像全体をカバーすることができた。
- シングルクリップ評価とマルチクリップ評価のフレーム数を同じにして
- FLOP数を同等にした場合
⬇
- シングルクリップ評価のほうが高い精度が得られる事がわかった。
これは、3DCNNが学習したフレーム数よりも多くのフレームで評価しても、より長距離の依存関係をモデル化することができることが一因であると考えられる。
既存のモデルでは、マルチクリップ評価が一般的なので、公平に比較するために、クリップごとではなく動画ごとのFLOP数を報告している。
しかし、シングルクリップ評価では、ネットワークのピークメモリ使用量が大幅に増加する可能性がある。
ストリームバッファは、この問題を解決し、MoViNetsが動画全体を埋め込んでいるように予測する頃を可能にし、マルチクリップ評価よりもピークメモリの使用量が少なくてすむ。
X3Dを再現し、各動画に対して10クリップx3空間クロップを行う評価戦略を30クリップとし、10クリップでは1空間クロップのみを行うものとする。効率を上げるために、推論中のMoViNetsにおける空間的な拡張や時間的なサンプルは一切行わない。
Comparison Results on Kinetics 600
MoViNets without Stream Buffers(ストリームバッファなしでの比較結果)
表2にstream bufferなしの比較結果を示す。表の列は、Top-1精度、モデルが負担する動画あたりのGFLOPs、入力動画フレームの解像度(ここでは2242を224に短縮)、動画あたりの入力フレーム(ここで、30×4は各実行で4フレームを入力として30クリップ評価することを意味する)、MoViNetsの探索空間における時間的なストライドτで決まるfps、及びネットワークのパラメータ数に対応している。
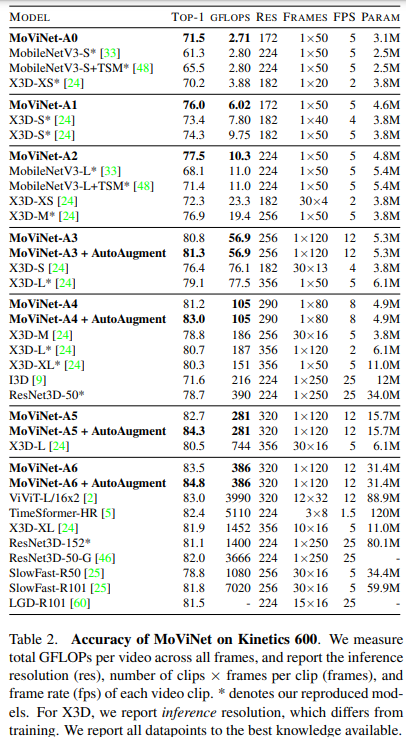
- MoViNet-A0は、MobileNetV3-Sと比較して、GFLOPsが少なく、精度が10%高い。
- MoViNet-A0は、精度とGFLOPsの両方においてX3D-Sを上回っている。
- MoViNets-A1は、X3D-SのGFLOPsと一致しているが、精度は、X3D-Sよりも2%高くなっている。
- MoViNets-A2は、30クリップのX3D-XSやX3D-MのGFLOPsのほぼ半分を使うことで、30クリップのX3D-XSやX3D-Mよりも少し高い精度を実現している。
- MoViNet-A5とMoViNet-A6は、ViViT やTimeSformerのような最近のTransformerモデルを含む、いくつかのSOTAビデオネットワークの性能を上回っている。
- AutoAugmentを搭載したMoViNet-A6は、84.8%の精度(事前学習なし)を達成しながらも、同等のモデルよりも大幅に効率が良い(多くの場合、1桁の差がある)。TimeSformer-HR のような完全なTransformer モデルと比較しても、MoViNetA6は精度で1%、使用するFLOP数で40%上回っている。
MoViNets with Stream Buffers
表3にstream bufferありの比較結果を示す。
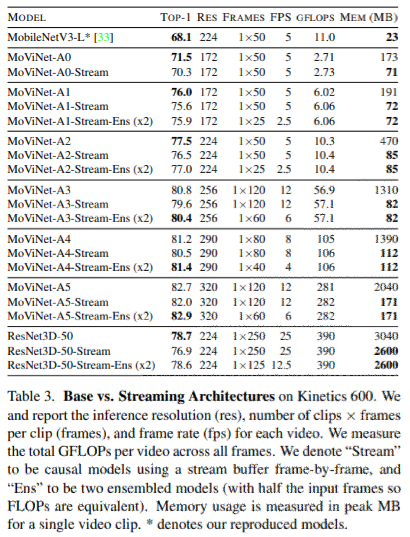
表3の最後の列に示されているように、因果関係のある操作をstream bufferを使用することで大規模なネットワーク(MoViNets A3~A6)のピーク時のメモリを1桁削減することができる。
さらに、図3では、ストリーミング・アーキテクチャのメモリに対する効果を視覚化している。
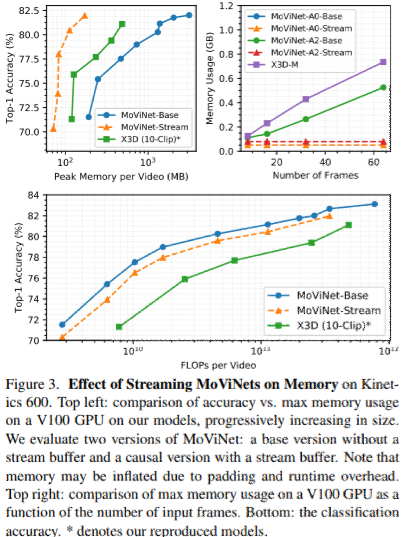
- 上左図から、マルチクリップ評価を採用しているX3Dと比較して、我々のMoViNetsはすべてのモデルサイズでより正確で、よりメモリ効率が高いことがわかる。
- 上右図から、入力受容野の総フレーム数をスケールアップしても、メモリが一定であることがわかる。
- 下図から、入力ビデオあたりのGFLOPsの観点から、ストリーミングMoViNetsが効率的であることがわかる。
- Stream bufferをResNet3D-50に適用したが、メモリ消費量はあまり変化なかった(overheadが多いから?)。
MoViNets with Stream Buffers and Ensembling
全てのモデルで1%の精度低下が見られただけで、時間的なアンサンブルを用いて精度を回復できた。(もとのモデルの半分のフレームレートで学習した2つのモデルをアンサンブルした場合の効果を報告。)
すべてのストリーミング・アーキテクチャで精度が向上しており、特にモデルのサイズが大きくなるにつれて、ストリーミング・アーキテクチャと非ストリーミング・アーキテクチャの間のギャップを埋めることができる。
注目すべき点は、先行研究とは異なり、アンサンブルは単に精度を高めるだけではなく、効率(GFLOPs)のバランスも取っているところ。
Comparsion Results on Other Datasets
fig4では、5つのデータセット全てでのMoViNetsの主な結果を、それぞれのデータセットで報告されているSOTAのモデルとともにまとめたものである。
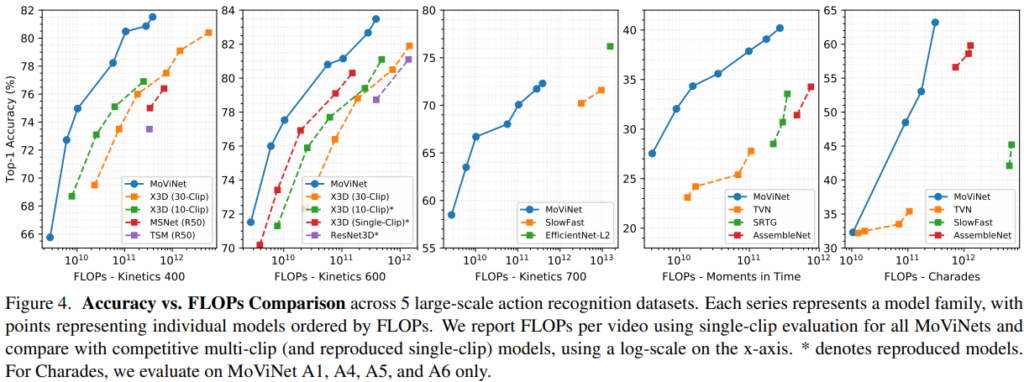
- Moments in Timeでは、低GFLOPsでTiny Video Networks(TVN)よりも5~8%精度が高く、MoViNet-A5は39.9%の精度を達成し、optical flowを使用するAssmbleNetを上回った。
- Charadesでは、MoViNet-A5は、63.2%の精度を達成し、optical-flowとobject-segmentationを追加入力したAssembleNet++を上回った。
Additional Analyses
MoViNet Operations
表4にいくつかの重要なMoViNetオペレーションに関するablation studiesを示す。
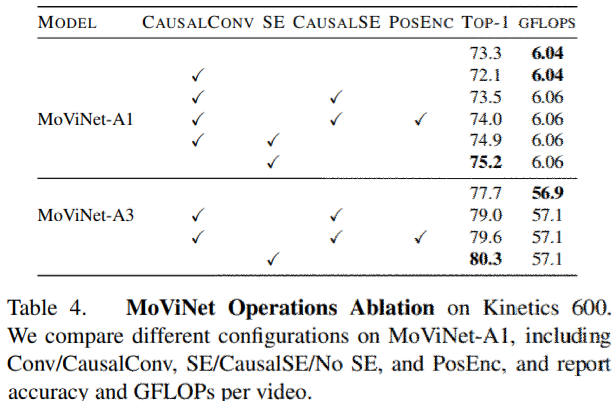
- SEを取り除くとMoViNet-A1の精度は2.9%低下。
- グローバルSEを用いたCausalConvよりもSEを用いないCausalConvのほうが、精度の低下が大きいことを示す。
- グローバルSEが、標準的なConvの役割の一部を担い、将来のフレームから情報を抽出できることを示す。
- CausalConvとCaousalSEを用いた完全なストリーミング・アーキテクチャに切り替えると、将来のフレームからの情報はもはや使用できず、精度は大きく低下するが、それでもSEなしのCausalConvよりは大幅に改善する。
MoViNet Architectures
表5にMoViNet-A2の構造の説明を示す。

最も注目すべき点は、このネットワークが、[2.5, 3.5]の範囲の大きなボトルネック幅の乗算器を好み、各層のあとでしばしばそれを拡大または縮小すること。(X3D-Mではベースとなる特徴の幅が広く、ボトルネックの定数の数は2.25と小さくなっている。)
探索されたネットワークは、バランスの取れた3x3x3のカーネルを好むが、後のブロックの最初のdownsampling層では5x3x3のカーネルを使う。最終段階ではほとんどが1x5x5の空間カーネルを使用しており、分類のための高レベルの特徴はほとんどが空間特徴量から得られることを示している。これはS3Dとは対照的。
Hardware Benchmark
MoViNets A0、A1、A2は、モバイル機器で最も現実的に使用されるであろう最速モデルである。これらのモデルとMobileNetV3を,x86 Intel Xeon W-2135 CPU(3.70GHz)を用いて,FLOPSとリアルタイム・レイテンシーの両方で比較したのが図5。
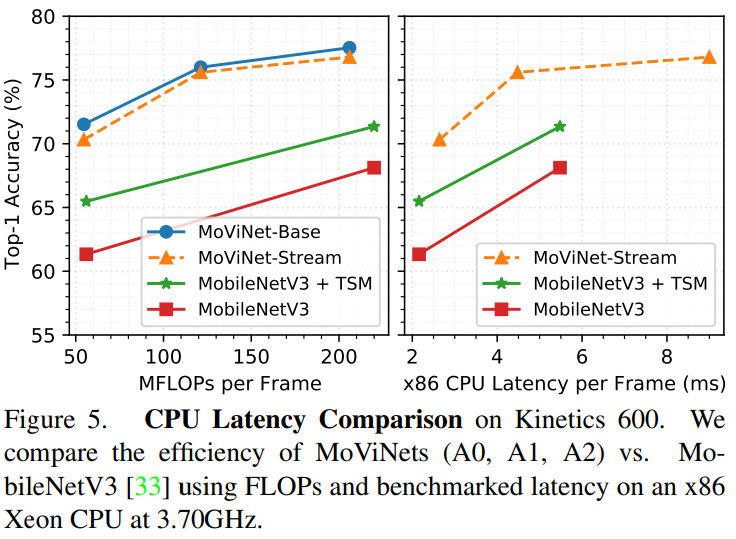
いずれのモデルも50フレームで評価。MoViNetsは、TSMのような時間的な変更を加えても、CPU上でより高速に動作し、同時により正確であると結論づけることができる。
表6には、Nvidia V100 GPUで動作するMoViNetsのベンチマークも示す。

- MobileNetV3はGPU上で我々のネットワークよりも高速に動作
- NASのFLOPs指数には限界があることを示す。
実際のハードウェアをターゲットにすることでより効率的にすることができるが、これは今後の課題。
Conclusion
- MoViNets は、さまざまなビデオ認識データセット間でうまく移行できる非常に効率的なモデルのセットを提供する。
- ストリーム・バッファと組み合わせることで、MoViNetsは、トレーニングと推論のメモリ・コストを大幅に削減するとともに、ストリーミング・ビデオでのオンライン推論をサポートする。
- MoViNetsを設計するための我々のアプローチが、将来および既存のモデルを改善し、その過程でメモリおよび計算コストを削減できることを期待。