【論文読み】ViViT: A Video Vision Transformer 日本語まとめ
忙しい人向け
どんな論文か
- Transformerだけを用いた動画分類モデルを提案。
先行研究と比べてどこがすごい
- Transformer baseの手法は、大規模な学習データセットが必要だが、学習中にモデルを効果的に正則化し、事前に学習した画像モデルを活用することで、比較的小さなデータセットでも学習できる方法を示した。
技術の手法やキモ
- 入力動画から時空間トークンを抽出し、それを一連のtransformer layerでエンコードする。
- 長いトークンシーケンスを処理するために、入力の空間的及び時間的次元を因数分解するモデルの効率的なバリエーションをいくつか提案。
どうやって有効だと検証した
- Kinetics400 and 600, Epic Kitchens, Something-Something v2, Moments in Timeなどの複数の動画分類ベンチマークでSOTA.
議論はあるか
手法の詳細
手法について以下の流れで解説する。
- Vision Transformerの概要について
- 動画からトークンを抽出する2つのアプローチを紹介。
- 動画分類のためのいくつかのtransformer-baseの構造について紹介。
Overview of Vision Transformers(ViT)
ViTはtransformerを2D画像の最小限の変更で処理できるようにしたもの。
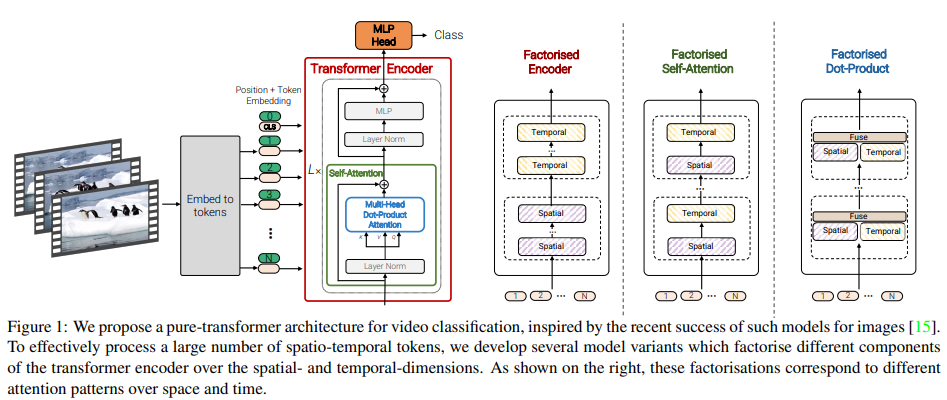
- ViTは、N個の非重複画像パッチ$x_i \in \mathbb{R}^{h \times w}$を抽出し、線形投影を行い、1次元トークン$z_i \in \mathbb{R}^{d}$にラスタライズする。
- トークンのシーケンスは以下のようになる。
- $z = [z_{cls}, E_{x_1},, E_{x_2}, \dots,E_{x_N}] + p (1)$
- $E$による投影は2次元畳み込みと等価である。
- $z = [z_{cls}, E_{x_1},, E_{x_2}, \dots,E_{x_N}] + p (1)$
- fig1に示すように、このシーケンスの前には、任意で学習した分類トークン$z_{cls}$が付加されており、エンコーダの最終層での表現は、分類層で使用される最終的な表現となる。
- さらに位置情報を保持するために、学習された位置埋め込み$p \in \mathbb{R} ^ {N \times d}$がトークンに追加される.
- その後のtransformerにおけるself-attention 演算が順不変であるため。
- トークンは、L個のtransformer層からなるエンコーダに渡される。各層$l$は、次のようにmulti-head self-attention, layer normalisation(NL), MLP blocksで構成されている。
- $y^l = MSA(LN(z^l)) + z^l (2)$
- $z^{l + 1}=MLP(LN(y^l)) + y^l (3)$
- MLPは非線形GELUによって分離された2つの線形投影からなり、トークン次元dはすべての層で固定されている。
- 最後に、線形分類器を用いて符号化された入力を
- $z^L_{cls} \in \mathbb{R}^d$が入力に前置きされている場合は、それに基づいて分類。
- 入力に前置きされていない場合は、すべてのトークンのグローバルな平均プールである$z^L$に基づいて分類。
ViTの基礎をなすtransformerは、入力トークン$z \in \mathbb{R} ^ {N \times d}$の任意のシーケンスで動作可能な柔軟なアーキテクチャである。
Embedding video clips
動画$V \in \mathbb{R}^{T\times H \times W \times C}$を一連のtoken $\tilde{z} \in \mathbb{R}^{n_t\times n_h \times n_w \times n_c}$にマッピングするためのシンプルな方法を2つ示す。その後位置埋め込みを加え、transformerの入力$z$を得るために$\mathbb{R}^{N \times d}$に変形する。
Uniform frame sampling
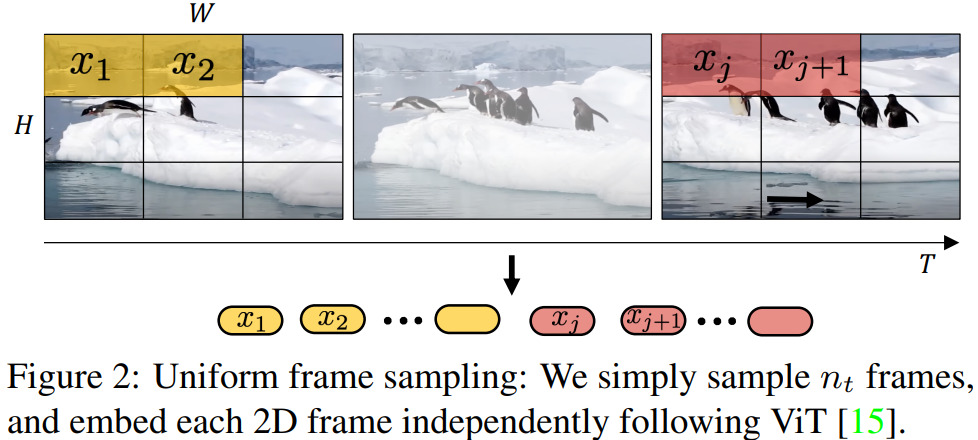
fig2に示すように、動画をトークン化する簡単な方法は、
- 入力動画クリップから$n_t$個のframeを一様にサンプリング
- ViTと同じ方法で各2Dframeを独立して埋め込む
- これらのトークンをすべて連結
各frameから$n_h \cdot n_w$個の非重複画像パッチを抽出した場合、$n_t \cdot n_h \cdot n_w$個のトークンがtransformer encoderに転送されることになる。
直感的には、ViTに従ってトークン化される大きな2D画像を単純に構築していると考えられる。既存研究で採用されている埋め込み手法であることに注意。
Tubelet embedding
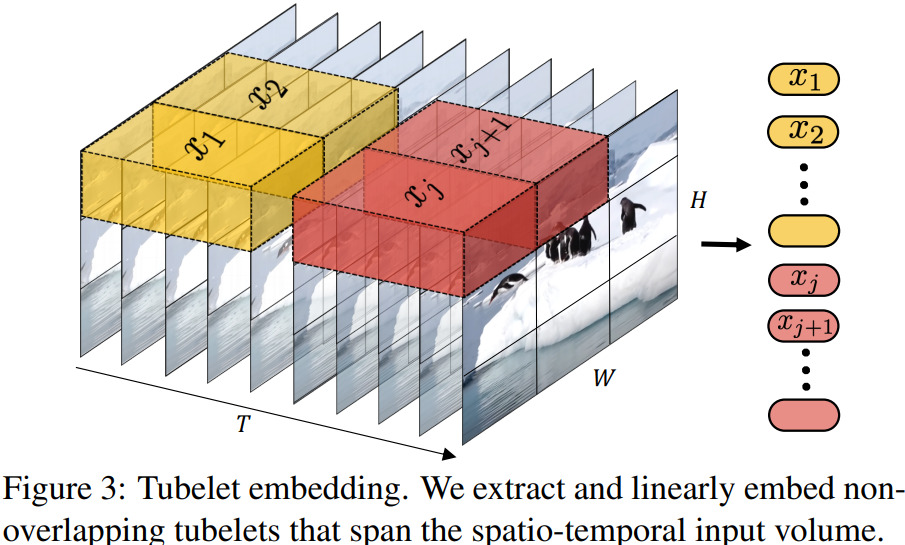
もう一つの方法は、fig3に示すように
- 入力から重なり合わない時空間的な"tubes(チューブ)"を抽出
- $\mathbb{R}^d$に線形投影
ViTの埋め込みを3Dに拡張したもので3D convに相当する。
$t \times h \times w$という寸法のチューブ$n_t = \lfloor \frac{T}{t} \rfloor,n_h = \lfloor \frac{H}{h} \rfloor,n_w = \lfloor \frac{W}{w} \rfloor$に対して、トークンは時間、高さ、幅のそれぞれの次元から抽出される。
チューブの寸法が小さいとトークンの数が多くなり、計算量が増える。
直感的には、トークン化の際に時空間情報を融合させるものであり、異なるフレームからの時空間情報がtransformerによって融合されるUniform frame samplingとは対照的。
Transformer Models for Video
fig1に示したとおり、本論文では複数の transformer baseの構造を提案する。まずはじめにViTを簡単に拡張して、すべての時空間トークン間のペアワイズ相互作用をモデル化した。つぎに、入力動画の空間的及び時間的次元をtransformer 構造の様々なレベルで因数分解する効率的なバリエーションを開発する。
Model1: Spatio-temporal attention
動画から抽出された時空間のトークン$z^0$をtransformerのencoderに通すだけ。(Jonint Space-Timeモデルでも同時に検討されていることに注意)
- 従来のCNN手法
- 層の数が増えるにつれて受容野が線形増加する
- 提案する各transformer層
- すべての時空間トークン間のすべてのペアワイズ相互作用をモデル化
- 第1層からの動画全体の長距離相互作用をモデル化している。
- すべてのペアワイズの相互作用をモデル化するため、Multi-Headed self-attention(MSA)はトークンの数に対して2次的な複雑さを持つ。
Model2: Factorised encoder

fig4に示すように、このモデルは2つの独立したtransformer encoderで構成されている。
- 空間的encoder
- 同じ時間的indexから抽出されたトークンの相互作用のみをモデル化する。
- 各時間的index $h_i \in \mathbb{R}^d$の表現は、$L_s$層の後に得られる。これは、encodeされた分類トークンであり
- 入力に前置されていれば$z^{L_s}_{cls}$
- そうでなければ、空間encoderが出力したトークンからのglobal average poolingである$z^{L_s}$
- フレームレベルの表現$h_i$は$H \in \mathbb{R} ^ {n_t \times d}$に連結された後、異なる時間indexのトークン間の相互作用をモデル化するために時間encoderに転送される
- 時間的encoder
- $L_t$transformer層で構成される
- 出力トークンが最終的に分類される。
この構造は、時間情報の"後期融合"に対応している。フレームごとの特徴を抽出し、それを最終的な表現に集約してから分類するなどのCNN構造と類似している。
- model 1よりもtransformer layerの数が多いのでパラメータは多い
- 計算の複雑さは、model 1が$\mathcal{O}((n_t \cdot n_h \cdot n_w)^2)$に対してmodel 2は$\mathcal{O}(((n_h \cdot n_w) + (n_t)^2)$のため、必要なFLOPの数は少ない。
Model3: Factorised self-attention
- Model 1と同じ数のTransformer layerを含んでいる。
- layer l ですべてのペアトークン$z ^l$にまたがってmulti-headed self-attentinを計算するのではなく、最初にすべての空間的self-attention(同じ時間的indexから抽出されたすべてのトークンの間)を計算し、それから時間的なもの(同じ空間的indexから抽出されたすべてのトークンの間)を計算するように演算を因数分解する。

transformerの各self-attention blockは上図のように時空間相互作用をモデル化しているが、2つのより小さな要素のセットに操作を因数分解することで、Model 1よりも効率的にModel 2と同じ計算量を達成している。
attentionを入力次元に因数分解することは、既存研究でも検討されており、動画の文脈では、"Divided Space-Time"モデルで同時に検討されていることに注意。この操作は、
- 空間的self-attentionを計算するためにtoken zを$\mathbb{R}^{1 \times n_t \cdot n_h \cdot n_w \cdot d}$から$\mathbb{R}^{ n_t \times n_h \cdot n_w \cdot d}$($z_s$と表記)に整形することで、効率的に行うことができる。
- 同様に、時間的self-attentin の入力である$z_t$は$\mathbb{R}^{ n_t \times n_h \cdot n_w \cdot d}$に整形される。
- leading dimensionを”パッチ次元”と仮定する
因数分解されたself-attentionは次のように定義される。
- $y^l_s = MSA(LN(z^l_s)) + z^l_s (4)$
- $y^l_t = MSA(LN(y^l_s)) + y^l_s (5)$
- $y^{l + 1} = MLP(LN(y^l_t)) + y^l_t (6)$
モデルのパラメータを3.4節で述べたように初期化しておけば、空間的self-attentionから時間的self-attention, 時間的self-attentionから空間的self-attentionの順序に間違いはないことがわかった。
ただし、Model 1と比較してself-attention layerと比較してself-attenton layerがつかされているため、パラメータの数が増えていることに注意。(式7)
このモデルでは、空間的次元と時間的次元の間で入力トークンを再構成する際の曖昧さを避けるために分類トークンを使用しない。
Model4: Factorised dot-product attention
Model 2, Model 3と同じ計算量だが、因数分解しないModel 1と同じパラメータ数を持つモデルを開発した。
空間次元と時間次元の因数分解はModel 3と似ているが、代わりにmulti-head dot-product attentionの計算を因数分解する。
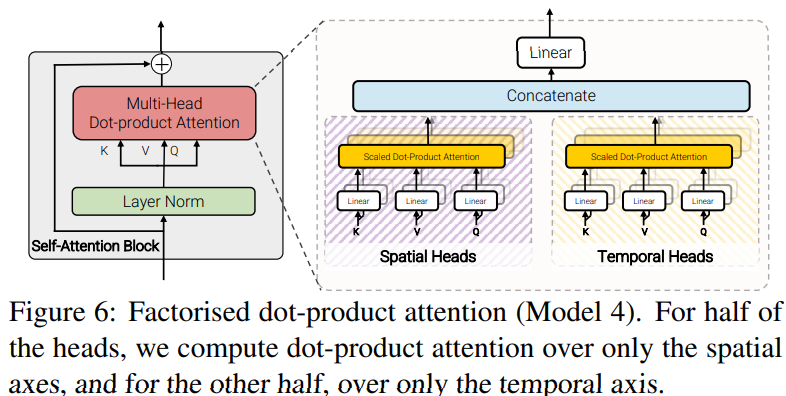
具体的には各トークンに対するattentionの重みを、空間次元と時間次元に渡って、異なるヘッドを使って別々に計算する。
- それぞれのヘッドのattnetionの計算を次のように定義する。
- $Attention(Q, K, V) = Softmax(\frac{QK^T}{\sqrt{d_k}})V. (7)$
- クエリ$Q=XW_q$キー$XW_k$、値$V=XW_v$は$X, Q, K, V \in \mathbb{R}^{N \times d}$の入力$X$の線形投影
- 因数分解されていないケース(Model1)では、空間的次元と時間的次元は、$N = n_t \cdot n_h \cdot n_w$としてマージされる
- ここでの目的は$K_s, V_s \in \mathbb{R}^{n_h \cdot n_w \times d}$と$K_t, V_t \in \mathbb{R}^{n_t \times d}$すなわちこれらの次元に対応するキーと値を構築することにより、同じ空間的及び時間的インデックスからのトークンのみに注目するように、各クエリのキーと値を修正すること。
- attention head の半分については、$Y_s = Attention(Q, K_s, V_s)$を計算して空間次元のトークンにattentionし、残りについては$Y_t = Attention(Q, K_t, V_t)$を計算して時間次元にattentionする。
- 各クエリごとにattention neighbourhoodを変更するだけなのでattention 計算は、因数分解されていない場合と同じ次元、すなわち$Y_s, Y_t \in \mathbb{R}^{N \times d}$となる。
- そして複数ヘッドの出力を連結し、線形投影法をもちいて、$Y = Concat(Y_s, Y_t)W_O$とする。
Initialisation by leveraging pretrained models
ViTは、大規模なデータセットで学習したときのみ有効であるということが示されている。(transformerには、CNNのような帰納的バイアスがないから)
しかし、Kineticsのような大規模動画データセットでもラベル付けデータは画像データセットと比べると少ない。
よって画像データセットでモデルを事前学習する。しかしいくつかの実用的な問題がある。特に、
- 画像モデルに存在しないパラメータや互換性のないパラメータをどのように初期化するか
ここでは、大規模な動画分類モデルを初期化するための効果的な戦略について説明する。
Positional embedding
- 位置埋め込みpはすべての入力トークンに加えられている。(式1)
- 事前学習の画像モデルに比べて、トークンの数がn_t倍多い。
- $\mathbb{R}^{n_w \cdot n_h \times d}$から$\mathbb{R}^{n_t \cdot n_h \cdot n_w \times d}$まで時間的に繰り返すことで位置埋め込みを初期化する
- 初期化時には、同じ空間インデックスをもつすべてのトークンは、同じ埋め込みをもち、その後fine-tuningされる。
Embedding weights, E
”tubelet embedding”の埋め込み重みEを使用する場合、埋め込みフィルタEは、3Dテンソルであり、事前学習モデル$E_image$とは異なる。
2次元から3次元の畳み込みフィルタを初期化する一般的な方法は、
$E = \frac{1}{t}[E_{image}, \dots , E_{image}, \dots , E_{image}]$
のように、時間次元に沿ってフィルタを複製し、それらを平均化することでフィルタを膨らませることである。
更に中心$\lfloor \frac{t}{2} \rfloor $以外のすべての時間的位置でEを0で初期化し、$\lfloor E = [0, dots, E_{image}, \dots, 0 \rfloor . (9)$とする中心フレーム初期化と呼ぶ戦略を検討する。
3D畳み込みフィルターは、初期化時には均一なフレームサンプリングのように効果的に動作するが、学習が進むにつれて、複数のフレームから時間情報を集約することをモデルに学習させることができる。
Transformer weights for Model 3
fig5のModel 3のtransformer blockは事前学習済みのViTモデルとは異なり、2つのmulti-head self-attention(MSA)モジュールを含んでいる。
空間的なMSAモジュールを事前学習したモジュールから初期化し、時間的なMSAのすべての重みをゼロで初期化して、初期化時に式5が残差接続として動作するようにする。
検証
検証に使用するのは、-
- ViT
- BERT
- 提案モデルのViT-Base(ViT-B, L=12, $N_H$=12, d=3072)
- ViT-Large(ViT-L, L=24, $N_H$= 16, d=4096)
- ViT-Huge(ViT-H, L=32, $N_H$=16, d=4096)
Lはtransformer layerの数。$N_H$はそれぞれのself-attention block の数。dは隠れ次元。
Ablation study
Input encoding
Model 1とViViT-Bを使って、Kinetics400で異なる入力エンコーディング方法の効果を検証する。

central frameを使用したtubulet embeddingが一番精度が高い事がわかった。
Model variants
Kinetics400,とEpic-Kitchens datasetを用いて提案したモデルのバリエーションを検証。
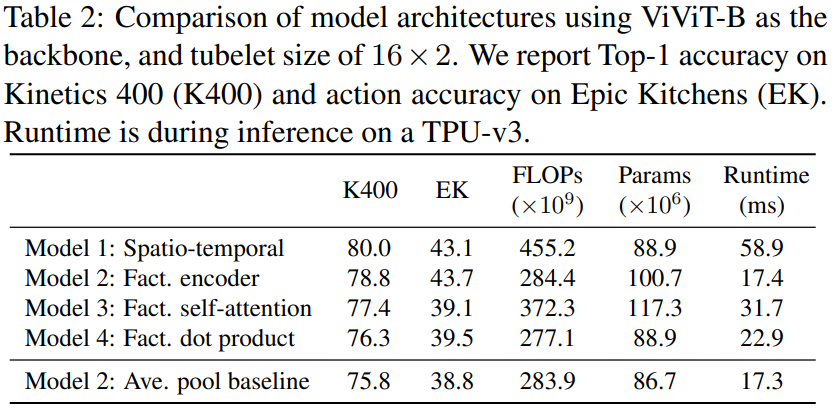
model 1はKInetics400で最も良い結果を示したが、Epic-Kitchenのような諸規模データセットでは因数分解エンコーダーであるModel 2が最も良い結果となった。
また、Model 2に基づいて、時間transformerを使用せずに空間エンコーダーの表現を分類前に単純に平均プールするベースラインも検討した(最後の行)。Epicでは大きく精度が低下したが、時間的関係を詳細にモデル化する必要があるからだと考えられる。
Model regularisation
Epic kitchenのようにデータセットの規模が小さいと過学習が起きるので、正則化手法を採用し、検証を行った。

table4各行には、その上の行にある全ての正則化手法が含まれている。各正則化手法を追加することによる段階的な改善が見られる。table2のEpic Kitchnes modelはすべての正則化手法が使用されている。Kinetics, Moments in timeのような大規模データセットでは、正則化手法を追加しなくても最先端の結果を得られるため使用していない。
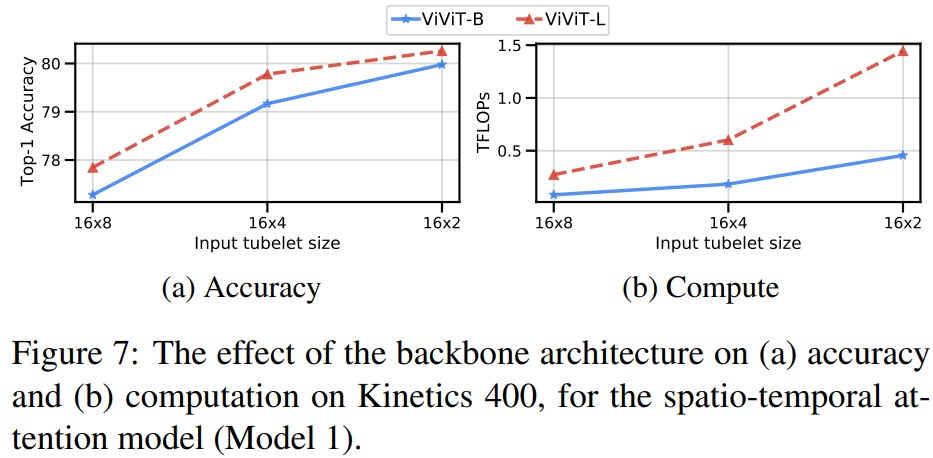
Varying the backbone
fig7は、因数分解されていない時空間モデルのViViT-BとViViT-Lを比較したもの。backboneの容量が大きくなるにつれて精度が一貫して向上していることがわかる。
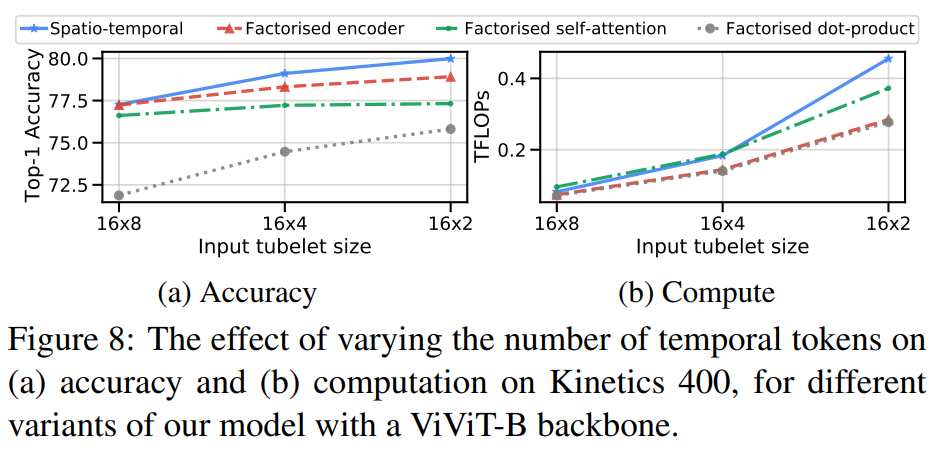
Varying the number of tokens
fig8の時間軸に沿ったトークンの数の関数として性能を分析した。入力チューブレットのサイズを小さくしてトークン数を増やすとすべてのモデルで精度が向上。
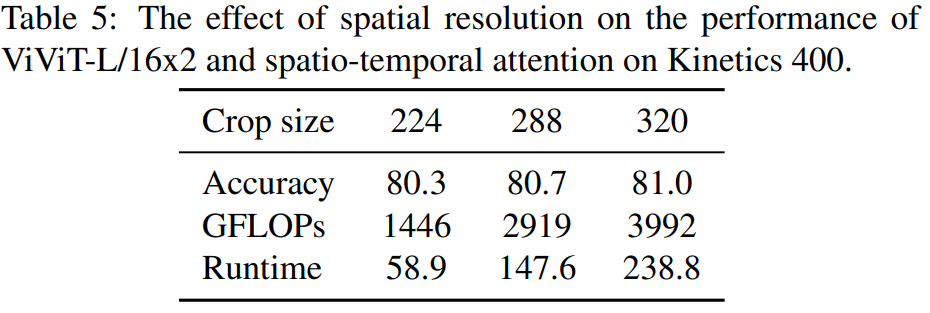
空間的なクロップサイズを224から320に増やすことでモデルに投入するトークンの数を変化させると精度と計算量が一貫して向上
Varying the number of input frames
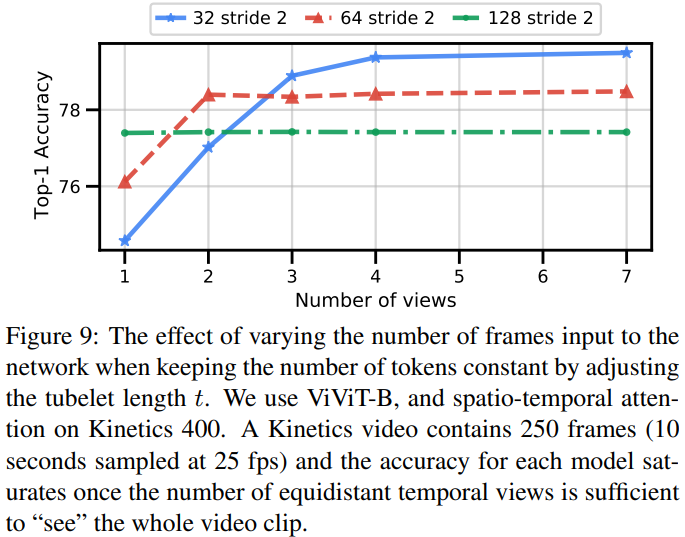
これまでの実験では入力フレーム数が32で固定されていた。1つのクリップを処理する計算量を固定したままフレーム数を変化させる。トークンの数が一定になるようにチューブレットの長さtを入力フレーム数に比例して増加させる。fig9では、フレーム数を多くして、それに伴いチューブレット長tを大きくするとネットワークがより長い時間的コンテキストを取り込むため、1つのクリップを処理する際の精度が向上することを示す。
Comparison to state-of-the-art
