【論文読み】Video Action Transformer Network, まとめ
FAIRのTimeSformerの論文を読んだので、関連研究で紹介されていたVideo Action Transformer networkを確認する。
忙しい人向け
どんな研究か
- 動画クリップの人間の行動を認識、定位するAction Transformer Networkを提案
先行研究と比べてどこがすごい
- すべてのピクセルのペアを比較するのではなく、比較の片方を人間の領域にすることで削減する。様々なbaseline構造に適用できる。
技術の手法やキモ
- transformerスタイルの構造を利用している。
- RPNで提案されたbboxの情報をもとに注目すべき領域を探し出し、クリップ上の情報を集約して行動を分類する。
どうやって有効だと検証したか
- Atomic Visual Actions(AVA)データセットを用いて学習、テストを行い、RGBの生フレームのみを入力としたときにmAPがSOTA
議論
- action transformerは、クリップ上の人を追跡することを学習する。
- シーン内の顔や手など注目している人の部分や、他の人物、関係する物体などにも注目する傾向がある。
- 人が増えるにつれて性能は低下する傾向にある。
- RGBだけで実験したが、optical flowなどを追加すれば更に性能が向上する可能性がある。
手法についての詳細
- 目的
- 動画のある時点(キーフレーム)で、すべての人物を検出し、その人物の行動をすべて分類する。
- 入力
- キーフレームを中心とした短い動画クリップ
- 出力
- キーフレーム内のすべての人間のbbox,行動のクラス。
- 処理の流れ
- Base modelとして3DCNNを利用して人間の特徴と、RP(region proposals)を生成。
- headで各提案に関連する特徴を利用してactionを予測し、よりタイトなbboxを回帰させる。(RPNとbboxの回帰はactionに依存しない。)
- RoIPoolの操作で各RPに対応する特徴表現を生成。
- 特徴を用いてboxをC個の行動クラスまたは背景(合計C+1)に分類。
- オフセットの4次元ベクトルに回帰させて、RPN 提案を人の周りのよりタイトなbboxに変換
Base network architecture
- base networkとして、Kinetics-400で事前学習したI3Dを使用。
- 入力の$T \times H \times W$が$T’ \times H’ \times W’ = \frac{T}{4} \times \frac{H}{16} \times \frac{W}{16} $にdownsamplingされる。
- RPNより提案された上位R(R=300)のboxを次に説明する分類headの入力として使用。
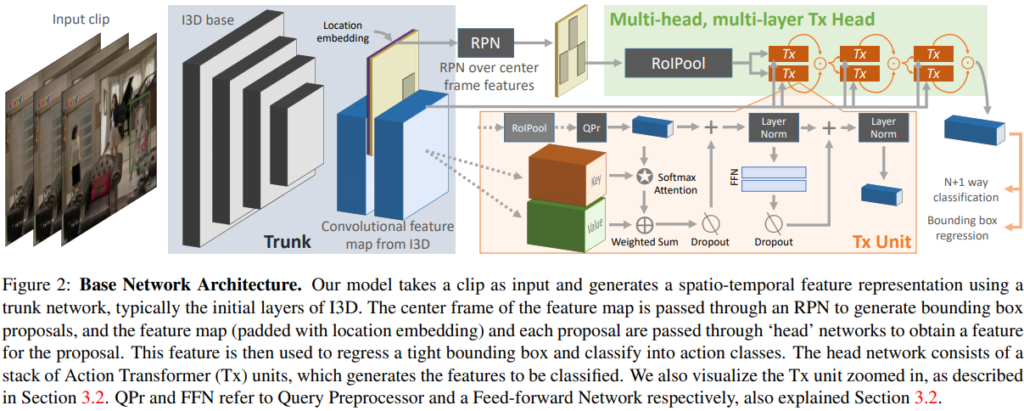
Action Transformer Head
- 本手法のhead 構造は、既存研究にヒントを得て再利用。
- RPNからの人物boxをクエリとして使用し、注目すべき領域を探し出し、クリップ上の情報を集約して行動を分類する。
Transformer
Transformerは、NLP分野で大きな成果を出し、最近CVの分野への応用が進んでいる。
- ある特徴をシーケンス内の他のすべての特徴と比較することでself-attentionを計算
- 特徴量を線形投影法を用いてクエリ(Q)とメモリ(キーと値, V&Q)の埋め込みにマッピング
- NLPでクエリは翻訳される単語、キーと値は、入力シーケンスとこれまでに生成された出力シーケンスの線形投影。
- 位置情報を組み込むために位置埋め込みも追加する。
Action Transfomrer
- RPNからの動画特徴とboxの提案を入力として受け取り、それをクエリ特徴とメモリ特徴にマッピングする。
- 分類される人物がクエリ(Q)、その人物の周りのクリップがキー(K)と値(V)に投影されたメモリ。
- クエリとメモリを処理して、更新されたクエリベクトルを出力
- 直感的には、self-attentionによってクリップ内の他の人やオブジェクトからのコンテキストがクエリベクトルに追加され、その後の分類を助ける。
- 複数のheadとlayerの積み重ねることができ、あるレイヤーの複数のheadからの出力を連結し、連結された特徴を次のクエリとして使用。
ユニットについて
- センタークリップから人物boxのRoIPool化された特徴を抽出し、それをクエリプロセッサ(QPr)と線形レイヤに通すことでサイズ1x1xDのクエリ特徴を得る。
- QPrは、まず1×1の畳み込みで次元を減らし、次に得られた7×7の特徴マップのセルを連結して、ベクトルにする。最後にこの特徴量マップの次元をリニアレイヤーを用いて128D(クエリマップや特徴マップと同じ)まで削減する。この手順をHighRes query preprocessingと呼ぶ。後でLowRes query preprocessing(特徴を空間的に平均化するだけ)と比較
- RPN提案rに対応する特徴$Q^{(r)}$を$\sqrt{D}$で正規化されたK個の特徴に対するdot積のattentionを使用し、その結果をV個の特徴の加重平均($A_{(r)}$)に使用。式にすると以下。
- $a^{(r)}_{xyt} = \frac{Q^{(r)}K^T_{xyt}}{\sqrt{D}}; A^{(r)} = \sum_{x,y,t}[Softmax(a^{(r)})]_{xyt} V_{xyt}$
- $A^{(r)}$にdropoutを適用し、それを元のクエリ特徴に追加する。結果として得られたクエリは、MLPとして実装されたFFN(Feed Forward Network), dropoutからなる残差分岐を通過する
- 最終的な特徴は、更にもう一つのLayerNormに渡され、更新されたクエリ(Q")が得られる。
fig2(Tx Unit)は上述の構造を示しており、次のように表すことができる。
$Q^{(r)’} = LayerNorm(Q^{(r)} + Dropout(A^{(r)}))$
$Q^{(r)"} = LayerNorm(Q^{(r)’} + Dropout(FFN(Q^{(r)’})))$
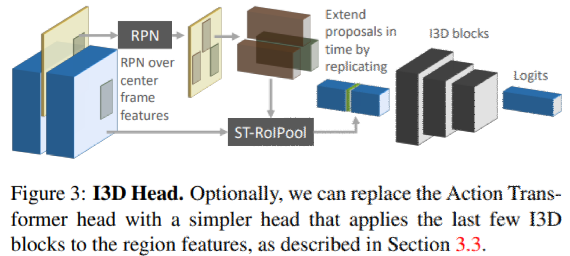
I3D Head
action transformer headの比較のために、コンテキストを抽出しない、よりシンプルなheadも構築した。
- 時空間RoIPool演算を用いてRPN提案に対応する特徴表現を特徴マップから抽出。
- boxを抽出して、チューブを形成することでRPを時間的に引き伸ばすことで実装。
- 対応するboxを使用して、各時点の特徴マップから特徴表現を抽出
- 特徴を積み重ねてチューブに対応する時空間的な特徴マップを得る
- I3Dの層(Mixed 5a~ Mixed 5c)に通す。
- 分類とbbox回帰のために線形層に渡す。
実験
AVAベンチマークを用いて、モデルを評価する。actionのローカライズと分類の2つの異なるタスクを実行する。
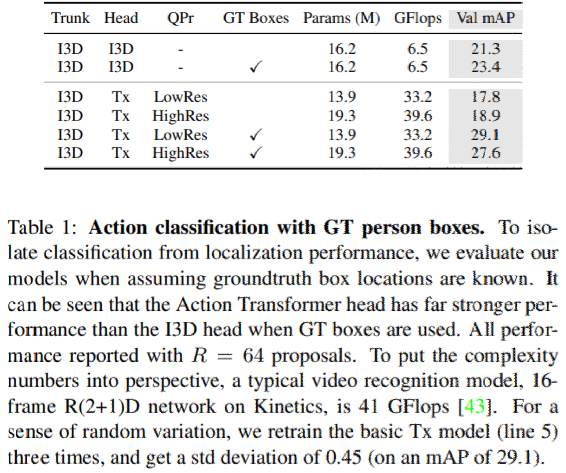
RPN提案をGT boxに置き換え残りはそのまま
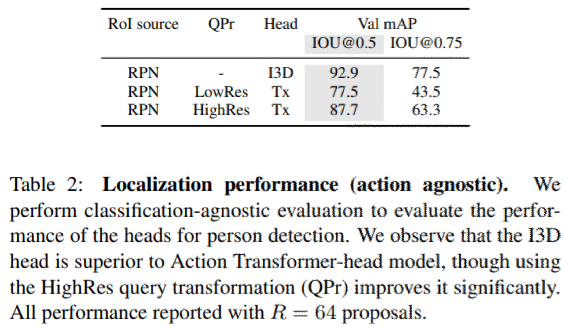
すべてのクラスラベルを単一のactive クラスラベルに変換することで、完全な分類を仮定し、問題を純粋なactiveな人物対背景の検出問題に落とし込んで性能を評価。
実験から得られた教訓
Action Transformer headはI3D headよりも優れている事がわかった。
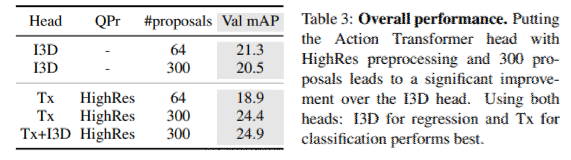
Ablation study
開発したモデルでは、クラスに依存しない回帰、データの拡張、Kineticsによる事前学習を行ってきた。3つの要素がどれだけ重要か1つずつ要素を取り除いて検証。3つの要素は重要であることがわかった。
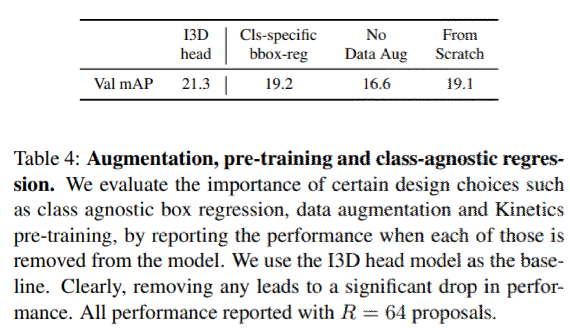
RPNで十分な数の提案を使用することについての重要性
表3を見ると提案数を300から64に減らすと、Action Transformerモデルのパフォーマンスが大幅に低下する。I3D headのときはあまり影響を受けない。
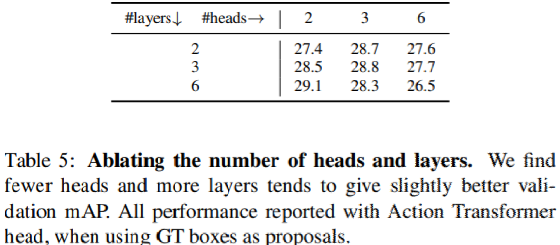
Action Transformerにおけるheadslayersの数
レイヤーごとに複数のヘッド、及び複数のレイヤーに容易にスタックできるように設計されている。表5では、headとlayerの数を変えたときの効果を評価。性能はほぼ同じだが、layerが増えheadが減るとわずかに良くなる傾向がある。そのためデフォルトで2-head 3-layerモデルを採用している。
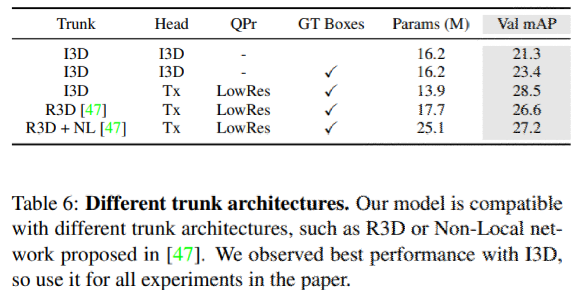
trunk architectureの入れ替え
様々なtrunk architecture の入れ替えの比較を表6に示す。
以前のSOTA手法との比較
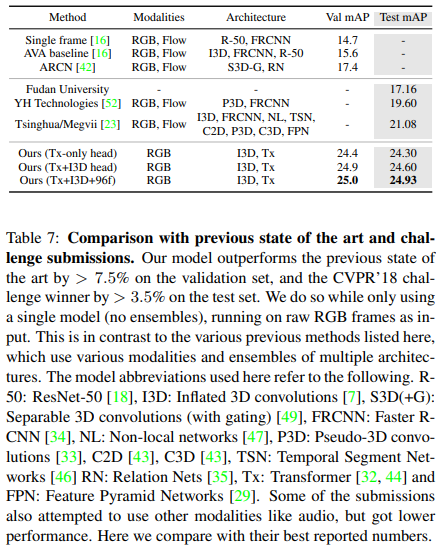
分析
Action Transformerモデルについての分析を行う。
- モデルによって学習されたkey, value埋め込みとattention mapを視覚化する。
- 特定のクラス、人の大きさ、数に対する性能を分析
- 一般的なfailure modesを可視化する。
学習された埋め込みとattention map128Dのキーとなる埋め込みとattention mapをfig4に示す。3D PCA投影を色分けして可視化。2-head 3-layer Action Transformerモデルの6つのheadのうち2つのheadを表示。attention mapでは、Tx headの最後の層にある2つのheadの平均softmax attentionを可視化している。

最初のheadでは、すべての人間が同じ色で意味的な埋め込みを示唆している。他のheadでは異なる色をしており、インスタンスレベルの埋め込みを示唆している。人物が関わる物体にも注目する傾向がある。
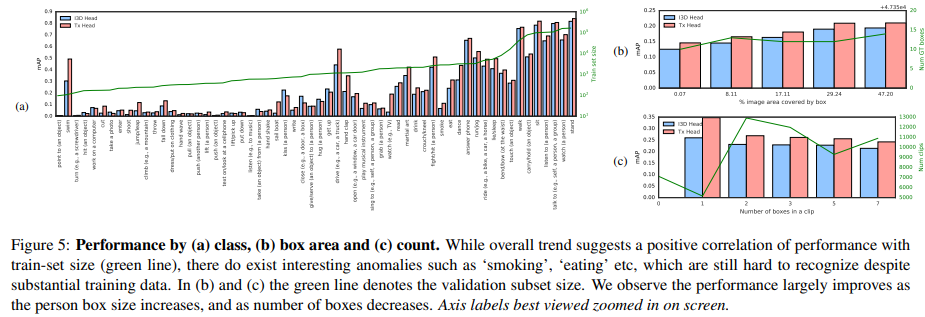
fig5(a)でクラスごとの性能を評価する。喫煙など、十分なデータ量があっても低いクラスもある。船をこぐ、テレビを見るなどは改善された。人物の文脈を考慮することで得られるものと考えられる。
fig5(b)ではGT boxが占める面積の割合で定義される、クリップ内の人物の大きさに関する性能を評価。すべてのGT boxをソートし、同じようなサイズのbinに分割することで求めた。
fig5(c)では、1つのクリップにラベル付けされたGT boxの数に対する性能を評価。人物の数が増えるにつれて性能が低下していることがわかる。
定性的な結果
fig6で成功例の視覚化をした。コンテキストを利用して、俳優を見るだけでは本質的に困難な人を見るなどの行動を認識することができる。

fig7では失敗例を示す。列は、(a)類似のactioninteraction,(b)アイデンティティ,(c)時間的位置。
