【論文読み】Pay Attention to MLPs 日本語まとめ
Pay Attention to MLPsを読んだ。GooleResearchの論文で、computer vision のタスクには、self-attentionはあまり必要ないということを示している。最近は、convolution vs transformerの議論が盛り上がっている印象がある。
忙しい人向け
- 単純なAttentionを使用しないゲート付きMLPのみを使用したgMLPを提案。
- 主要な言語、視覚タスクでTransformerと同程度の性能を発揮。
- self-attentionがvision transformerにおいて重要ではないことを示した。
- BERTでは、事前学習のperplexityでTransformerと同等の性能を達成し、下流タスクでは上回った。
- gMLPモデルを大幅に大きくすることで、Transformerとの差を縮めることができる。データ量や計算量が増えてもTransformerと同等に拡張できることがわかった。
Model
gMLPは、同一のサイズと構造を持つL個のブロックのスタックで構成されている。$x \in \mathbb{R}^{n \times d}$を配列長n、次元dのトークン表現とすると、各ブロックは次のように定義される。
$Z = \sigma{XU}$ (1)
$\tilde{Z} =s(Z)$ (2)
$Y = \tilde{Z}V$ (3)
- $\sigma$: GeLUのような活性化関数
- $U, V$ : TransformerのFNNものもと同じ、チャネル次元に沿った線形投影(例えばBERT向けのshapeは768×3072と3072×768)
定式化における重要な要素は、空間的な相互作用を捉える層である$s(-)$
$s$がIDマッピングである場合、上記の変換は通常のFNNに縮退し、個々のトークンはトークン間の通信なしに独立して処理される。そのため、トークン間の複雑な空間的相互作用を捉えることができる優れた$s$を設計することが重要。全体的な深さ方向の畳込みとして$s(.)$を定義する反転ボトルネックにヒントを得ている。
Transformerと異なり、位置埋め込みを必要としない。($s(.)$に取り込まれるから。)
提案モデルは、BERT(NLP用)及びViT(視覚用)と全く同じ入力及び出力フォーマットを使用する。
- 例えば、言語タスクの微調整を行うときには、複数のセグメントを連結したあとにパディングを行い、予測値は予約された<cls>記号の最後の層の表現から推論される。既存のTransformerの実装との互換性のため。
Spatial Gating Unit
トークン間の相互作用を可能にするためには、layer(.)が空間次元上の縮退操作を含むことが必要である。単純なオプションは、線形投影である。
$f_{W,b}(Z) = WZ + b$(4)
ここで、$W \in \mathbb{n \times n}$は、配列の長さnと同じ大きさの行列である。bは、行列でもスカラでも良いバイアス項を意味する。
例えば、入力配列が128個のトークンを持つ場合、空間投影行列Wの形状は、128×128となる。本研究では、空間相互作用ユニットをその入力と空間的に変換された入力の乗算として定義する。
$s(Z) = Z \odot f_{W, b}(Z)$ (5)
式(5)のs(.)は、学習開始時にはほぼ同一のマッピングとなっている。この初期化によって、学習の初期段階では、各gMLPブロックは通常のFNのように振る舞い、各トークンは独立して処理され、トークン間の空間情報が徐々に注入される。
更に、GLUで一般的に行われているように、ゲーティング関数と乗算バイアスのためにZをチャネル次元に沿って2つの独立した部分$(Z_1,Z_2)$に分割することが効果的であることがわかる。
$s(Z) = Z_1 \odot f_{W,b}(Z_2)$(6)
また、経験的に大規模なNLPモデルの安定性を向上させるために、W,bの入力を正規化する。これによって図1に示したようなユニットが得られ、これをSpatial Gating Unit(SGU)と呼ぶ。表3では、SGUを他のいくつかのs(.)と比較したablation studiesを示す。SGUがよく機能し、self-attentionとの性能差を縮めていることがわかる。
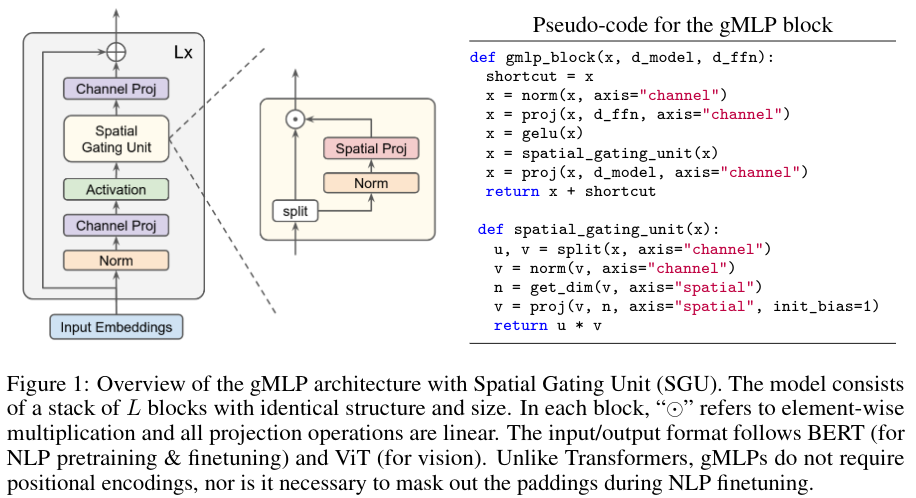
Image Classification
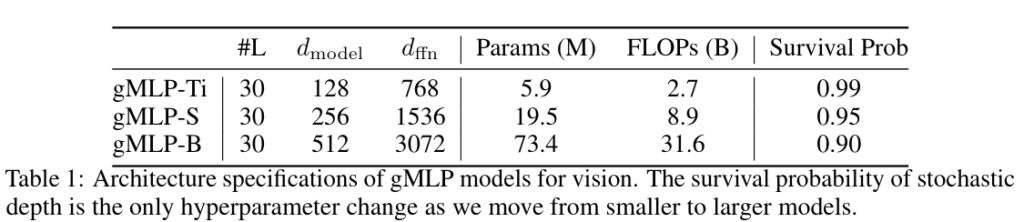
表1にgMLP画像分類モデルの構成をまとめた。
入力プロトコルは、VIT/B16に準拠している。画像は、16×16のパッチに変換される。正則化はDeiTで使用されているものと同等のものを適用。大規模なチューニングを避けるために表1では、モデルのサイズが小さいものから大きいものへと移行する際に、stochastic depthの強度のみを調整している。その他のパラメータは3つのモデルで共通。
ImageNetの結果は、表1と図2にまとめた。gMLPはDeiT、すなわち正則化を改善して学習したViTと同等の性能を達成。画像分類においてtransformerと同等のデータ効率を実現できる。実際適切にモデルが正則化されている場合、attentionの有無ではなく、容量との相関が高い。
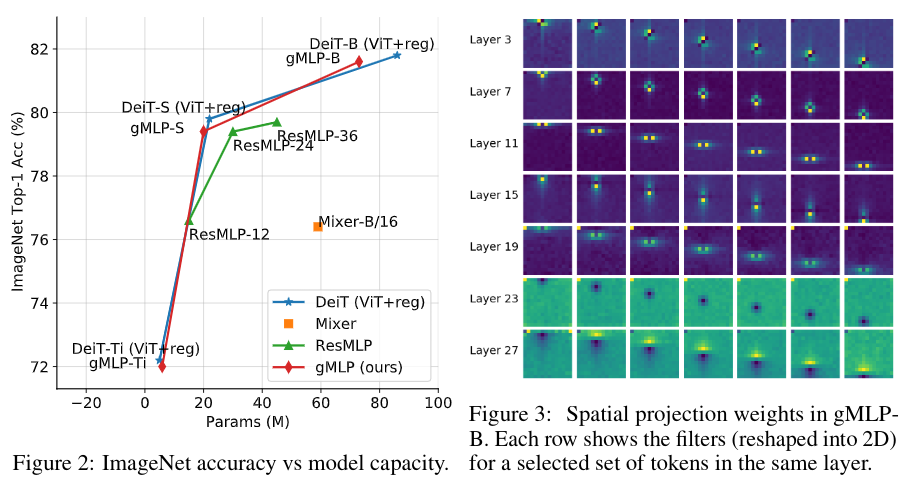
gMLPの精度とパラメータのトレードオフは、同時に提案されているMLPのような構造を凌駕している。gMLPはTransformerと競合するものの、既存のConvNetモデルやhybrid attentiveモデルには及ばないことがわかっている。
Masked language modeling with BERT
Masked language modeling taskに関する実証実験を行った。入出力フォーマットは、BERTに準拠。Transformerベースのモデルと異なり、位置埋め込みは使用していない。gMLPブロック内の<pad>トークンは、モデルがすぐに無視するようになるため、微調整の際にマスクアウトする必要はないと考えている。
ablationでは、C4のRealNews-like subsetを使用。バッチサイズ2048, 最大長128, 125k stepでモデルを学習。主な結果については、バッチサイズ256, 最大長512, 100万stepでC4データセット全体を用いてモデルを学習。
Ablation: The Importance of Gating in gMLP for BERT’s Pretraing
ゲーティングの重要性についてablation studyのベースラインを設定している。
- Transformer 構造及び学習可能な絶対位置埋め込みを有するBERT
- T-5形式の学習可能な相対位置バイアスを有するBERT.
- layerとheadの両方に特化している。
- 上記と同じだが、ソフトマックス内のすべてのコンテンツに依存する用語を削除し、相対位置バイアスのみを保持。
- transformerの単純なnon-attenitonの変形であり、Synthesizerともみなせる。
これらのベースラインを同程度のサイズのいくつかのバージョンのgMLPと比較したのが表3。SGUはperplexityにおいて他のものより優れている。SGUを用いたgMLPは、Transformerと同等のperplexityを達成。

gMLPで学習した空間投影重みを図4に示す。

表4では、BERTにおけるTransformer及びgMLPのモデル容量の増加に伴うスケーリング特性を調査した。モデルの深さを{0.5, 1, 2, 4}xの係数でスケーリングし、検証セットでのMLMの複雑さ、及びGLUEの2つのタスクdevセットでの微調整の結果を報告。
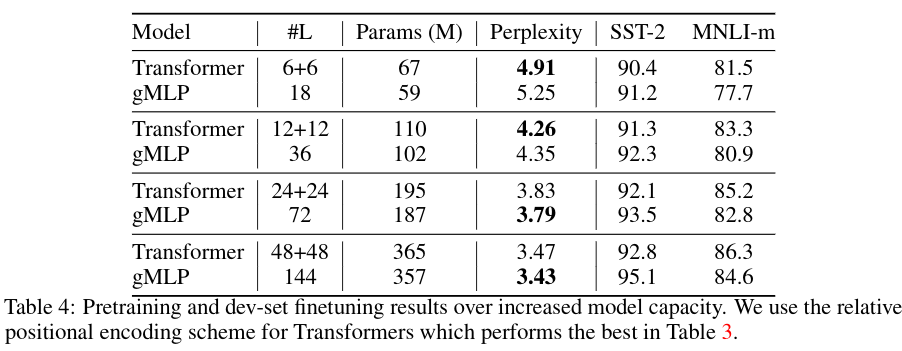
- 十分に深いgMLPは同程度の容量を持つTransformerに匹敵し、凌駕する事がわかった。
- perplexity-parameter 関係はほぼべき乗則に従っている。(図5左)
- NLPタスクのfine-tuning性能は、perplexityだけでなく、アーキテクチャの帰納的バイアスにも依存することを示唆する。
- モデルの容量を大きくすることでTransformerとgMLPのギャップを埋められる。(下流の指標に対するモデルのスケーラビリティはself-attentionの有無に依存しない。)(図5)

これまでの結果から、self-attentionは、MLMのperplexityやスケーラビリティを達成するためには必要な要素ではない事がわかった。一方でNLPのfinetuning taskでは、gMLPがTransformerよりも劣ることもわかった。(表4)
AttentionのgMLPのゲーティング機能に小さなself-attentionブロックを取り付けたハイブリッドモデルで実験を行った。(図6)

図7では、前処理のperplexityとfinetuningの間のキャリブレーションプロットを介して、MLMモデルの移植性を調査。BERT base, gMLP, そのハイブリッド版AMLPで、64dの単一head attentionを使用(図6)
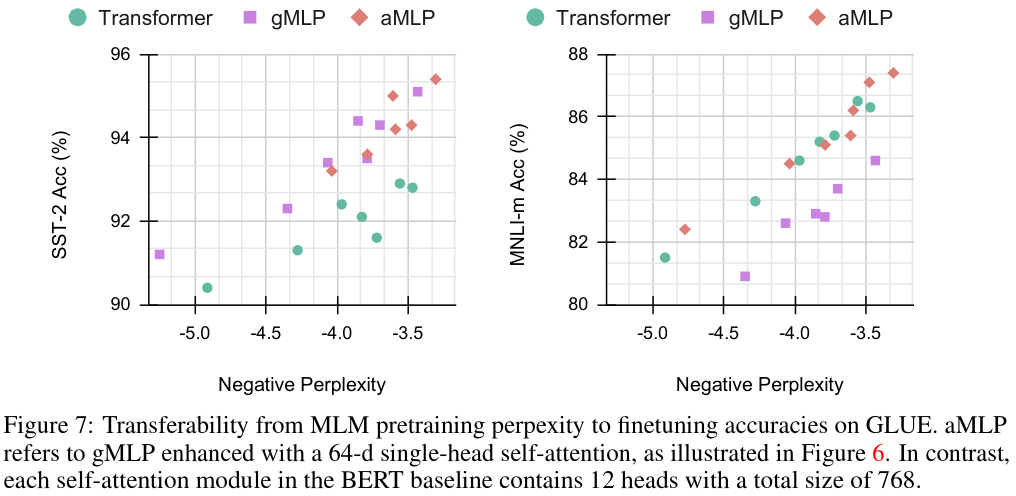
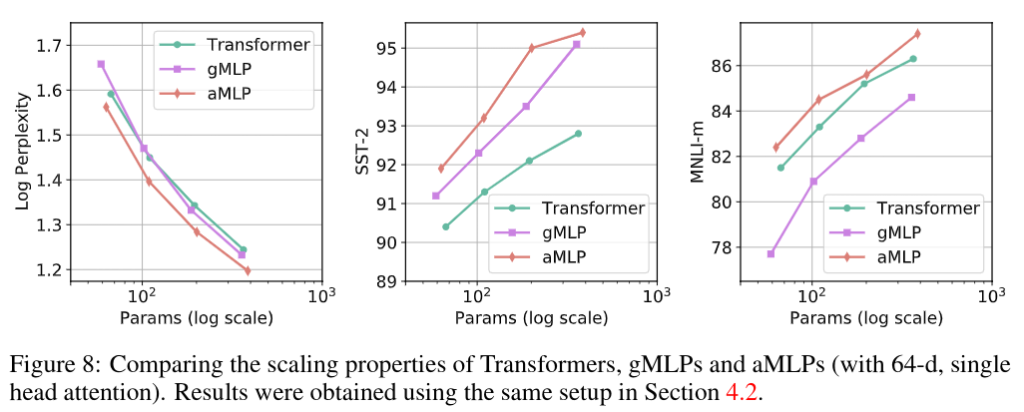
図8では、3つのスケーリング特性をまとめた。aMLPはTransformerのそれぞれのfinetuning taskにおいて常に上回った。
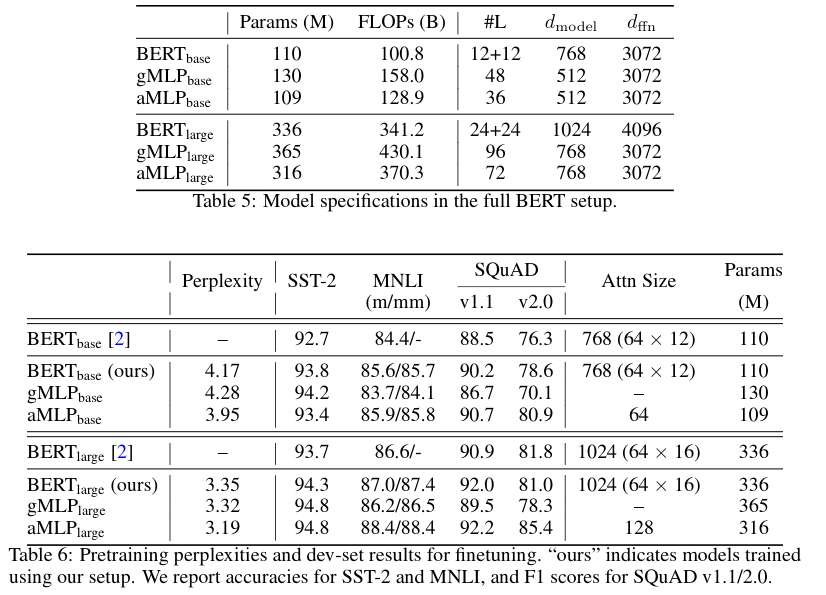
以下は、完全なBERT設定における事前訓練とfinetuningの結果(表6)。モデルの仕様は表5。
結果が示唆すること
- Transformersのmulti-head attentionの能力は、ほとんどが冗長であり、大部分はgMLPの空間ゲートユニットで捉える事ができる。
- gMLPの空間ゲートユニットの帰納的バイアスと微小なattentionが互いに補完しあっている。
Conclution
- 一般的にはあまりattentionが必要ないことを示唆した。
- ゲーティングを備えたMLPの単純な変形であるgMLPがBERTの訓練前の難解さとViTの精度の点でTransformerと競合できることを示唆。
- BERTのfinetuningについては、gMLPはSQuADのような困難なタスクでもattentionを使用せずに良い結果を出せた。
- gMLPにほんの少しのsingle-head attentionを混ぜることで、モデルサイズを大きくすることなく優れたアーキテクチャを実現。