【論文読み】TimeSformer論文解説まとめ
論文 Is Space-Time Attention All You Need for Video Understanding?についてまとめた。忙しい人向けと論文全体の精読の2部構成。
忙しい人向け
FAIRのブログをもとに要点をまとめた。
- どんな研究か
- Transformerを用いた動画を理解するための最初のアーキテクチャTimeSformerを提案。
- 結果
- Kinetics-400 action recognition datasetなどでSOTA
- 最新の3DCNNと比較してTimeSformerは3倍高速、推論に必要な計算量は、10分の1未満
- TiemSformerのスケーラビリティによって、遥かに長い動画クリップで遥かに大きなモデルの訓練が可能になった。
- 構造
- Transfomer modelで使用されるself-attention 構造によって動画全体の時空間依存関係を捉えることができる。
- 入力動画を個々のフレームから抽出された画像パッチの時空間シーケンスとして解釈する。
- 時間的attentionと空間的attentionを別々に適用するdivided space-time attentionを提案し、低い計算コストを維持。
- 動画を重複しないパッチの小さなセットに分解
- パッチのすべてのペア間の徹底的な比較を回避するself-attentionの形式を適用
- 研究の重要性について
- 3D CNNでは数秒の長さの動画セグメントのみを使用できたが、TimeSformerはそれよりも遥かに長いクリップで訓練できる
- AR/VRなどへの研究分野への貢献
次に原論文を以下にまとめた。
1. Introduction
近年NLPの分野で、self-attentionに基づく手法が提案された。訓練時に単語同士の長い範囲の関係性を捉えることができるためにTransformerのようなself-attntion構造は、翻訳を含む様々な言語タスクにおいてSOTAを達成した。
NLPと動画理解には、いくつかの共通点がある。
- 基本的には連続している。
- NLPでは、ある単語を理解するにあたってその単語を文の中の他の単語と関連付ける必要がある。
- 動画では短時間のセグメントにおける行動を識別するには、動画の他の部分との関連付けが必要である。
よってNLPのlong-range self-attentionは、動画のモデリングに非常に有効であると期待される。
現状動画ドメインでは、2D, 3DのCNNモデルが時空間特徴学習において代表的。
self-attentionを畳み込み層の上に適用した研究はあるが、self-attiontionだけのブロックで構築する試みは報告されていない。
本研究では、畳み込み演算子をself-attentionに完全に置き換えることで性能の高いモデルを構築することができるか問題提起する。
提案モデルは、動画分析のためのCNNモデルに内在するいくつかの問題点を克服できる可能性がある。
- 強い帰納的バイアス(局所結合性、平行移動等価性)は、少量のデータセットでは、有益であるが、十分なデータが有り、例からすべてを学習できる環境においては、モデルの表現力を過度に制限する可能性がある。
- ▶transformerは帰納的バイアスをあまり制限しないので、表現できる関数の種類が増える。
- 畳み込みカーネルは、短距離の時空間情報を捉えるように設計されている。受容野を超えた依存性をモデル化することはできない。層が深くなると、自然に受容野が拡大するが、これは短距離の情報の集約によって長距離の依存性を捉えるので本質的に制限がある。
- ▶transformerは、従来のCNNフィルターの受容野を遥かに超えて、すべての時空間の位置で特徴の活性化を直接比較することによって局所的な依存性とグローバルな依存性の両方を捉えることができる。
- GPUの進歩にも関わらず、Deep CNNの学習には、特に高解像度や、長時間の動画に適用する場合、非常にコストがかかる。
- ▶静止画領域における最近の研究では、transformerはCNNに比べて学習と推論が高速であることが実証されており、同じ計算領域でより大きな学習性能を持つモデルを構築することが可能になっている。
self-attentionの構造を画像空間から時空間の3次元に拡張することで画像モデルのVision Transformer(ViT)を動画に適応させる。
提案モデルをTimeSformerと名付ける
- 構造
- 映像を個々のフレームから抽出されたパッチのシーケンスとしてみる。
- ViTと同様に、各パッチは、埋め込みに線形にマッピングされ、位置情報が付加される。
- NLPで単語から計算されるトークンの特徴と同様に、Transformerのencoderに供給できるトークン埋め込みとして解釈できる。
- 標準的なTimeSformerの欠点
- トークンのすべてのペアに対して類似性尺度を計算する必要があるため、計算コストが大きくなる。
- 動画の時空間構造を無視してしまう。
- 改善点
- 時空間ボリューム上でのスケーラブルなself-attention設計をいくつか提案し、大規模な行動分類データセットで経験的に評価。
- 最も良かったのは、ネットワークの各ブロック内で時間的attentionと空間的attentionを別々に適用するdivided attention。
- 時空間ボリューム上でのスケーラブルなself-attention設計をいくつか提案し、大規模な行動分類データセットで経験的に評価。
- 性能
- この分野のSOTAに匹敵する精度。
- 何分もの動画の長距離モデリングに効果的に使用できることも示す。
2. Related Work
静止画分類のためにself-attentionを畳み込み演算子と組み合わせて、あるいはその完全な代替として使用する研究に影響を受けている。
- 画像分類のためにself-attentionとCNN使用。
- Wangら、Non-Local Networks
- self-attentionを効果的に一般化するnon-localな平均を採用。
- Belloら、2D self-attention 構造
- CNNをself-attentionで補強するために使う
- 物体検出のためにCNNマップ上にself-attentionを使用
- HuらのRelation Networks
- CarionらのDETR
- CNNの代わりにself-attentionを活用
- Parmarら, Ramachandranら, Cordonnierら
- 個々のピクセルをクエリとして使用
- 計算コストと、少ないメモリ消費量を維持するためにローカルな近隣に制限するか、画像を大幅にダウンサイジングする。
- フル画像へのスケーラビリティの代替戦略
- Childらのsparse key-value sampling
- Hoらのself-attentionを空間軸に沿って計算するように制約する手法。
- 画像をパッチのシーケンスに分解し、これらのパッチ埋め込みをtransformerに与える
- DosovitsiyらのVision Transformers(ViT)(本研究は、このViTの設計をもとにして動画に拡張。)
- Parmarら, Ramachandranら, Cordonnierら
- Transformerを動画生成に利用
- Weissenbornら
- ▶しかしself-attentionを排他的な構成要素として活用した動画認識構造は知られていない。
- Weissenbornら
- 様々なタスクでCNN特徴マップ上にtransformerを適用した例
- 行動の定位と認識(Girdharら)
- 動画分類(Wangら)
- グループ行動認識(Gavrilyukら)
- 様々な動画言語タスクで動画CNNと組み合わせたtext transformerの研究
- キャプション(Zhouら)
- 質問応答(Yangら)
- 対話(Leetら)
- マルチモーダルvideo-text transformer
- Sunら, Liら
- 言語ドメインから適応されたマスクトークンプレテキストタスクを採用。教師なしの方法で学習または事前学習されている。
- Sunら, Liら
3. The TimeSformer Model
Input Clip(入力クリップ)
入力クリップとして、以下のような大きさH x WのF個のRGB framesを取る。
$$X \in \mathbb{R}^{H \times W \times 3 \times F}$$
Decomposition into patches(パッチへの分解)
ViTにしたがって、それぞれのフレームを重複しないN個のパッチに分解する。サイズはPxPで、N個のパッチがフレーム全体に及ぶようにする。すなわち以下のようになる。
$$N = HW/P^2$$
- これらのパッチをベルトル$x_{(p,t)} \in \mathbb{3P^2}$に平坦化する。
- p = 1, …,Nは空間的な位置を表す。
- t = 1, ….,Nはフレームに対するインデックスを表す。
Linear embedding(線形埋め込み)
各パッチ$x(p,t)$を学習可能な行列$E \in \mathbb{R}^{D \times 3P^2}$によって埋め込みベクトル$z^{(0)}_{(p,t)} \in \mathbb{R}^D$に線形にマッピングする。
$$z^{(0)}_{(p,t)} = Ex_{p,t} + e^{pos}_{(p,t)} (1)$$
- $e^{pos}_{(p,t)} \in \mathbb{R}^D$は各パッチの時空間的な位置をencodeするために追加された学習可能な位置埋め込み。
- p = 1, …, N, t = 1, …, F に対する埋め込みベクトル$z(0)$のシーケンスがTransformerの入力となる
- FはTransformerへの入力で、NLPのText Transformerに供給される。
- 埋め込みwordstokensのシーケンスと同様の役割を果たす。
- BERT Transformerと同様にシーケンスの最初の位置に分類トークンの埋め込みを表す特別な学習可能ベクトル$z^{0}_{0, 0} \in \mathbb{R}^D$を追加。
Query-Key-Value computation(クエリ,キー,バリューの計算)
本手法のTransformerは、L個のencoding blockから構成されている。各ブロックでは、先行するブロックによって符号化された表現$z$から各パッチについてquery, key, valueが計算される。
- $q^{(l,a)}_{(p,t)} = W^{(l,a)}_{Q}LN(z^{(l-1)}_{(p,t)}) \in \mathbb{R}^{D_h} (2)$
- $k^{(l,a)}_{(p,t)} = W^{(l,a)}_{K}LN(z^{(l-1)}_{(p,t)}) \in \mathbb{R}^{D_h} (3)$
- $v^{(l,a)}_{(p,t)} = W^{(l,a)}_{V}LN(z^{(l-1)}_{(p,t)}) \in \mathbb{R}^{D_h} (4)$
- LN()は、LayerNorm
- a = 1,…, Aは複数のattention headに対するindex
- Aはattention headの総数
- 各attention headの潜在次元は、$D_h = D/A$に設定
Self-attention computation(self-attentionの計算)
self-attentionの重みは、dot積によって計算される。クエリパッチ$(p,,t)$に対するself-attentionの重み$\alpha ^{(l,a)}_{(p,t)} \in \mathbb{R}^{N \ F+1}$は次のように与えられる。
$\alpha ^{(l,a)}_{(p,t)} = SM(\frac{q^{(l,a)}_{(p,t)}} {\sqrt{D_h}}^T \cdot [k^{(l, a)}_{(0,0)} \{ k^{(l,a)}_{(p’,t’)}\}_{p’=1,…N \\ t’=1,…,F}]) (5)$
SMは、Softmax 関数を表す。一つの次元でattentionを計算する場合、大幅に計算量が減少する。空間attentionを例にすれば、計算は同じフレーム内のN+1個のquery-keyとの比較だけになる。
$\alpha ^{(l,a)space}_{(p,t)} = SM(\frac{q^{(l,a)}_{(p,t)}} {\sqrt{D_h}}^T \cdot [k^{(l, a)}_{(0,0)} \{ k^{(l,a)}_{(p’,t)}\}_{p’=1,…N }]) (6)$
Encoding
ブロック$l$でのencoding$z^{(l)}_{(p,t)}$は、まず、各attention headからのself-attention 係数を用いてvalueベクトルの加重和を計算することで得られる。
$s ^{(l,a)}_{(p,t)} = \alpha ^{(l,a)}_{(p,t),(0,0)} v^{(l,a)}_{(0,0)} + \sum_{p’=1}^{N}\sum^{F}_{t’=1} \alpha^{(l,a)}_{(p,t),(p’,t’)}v^{(l,a)}_{(p’, t’)} (7)$
そして、すべてのheadからのベクトルの連結を投影し、各演算後の残差接続を使用してMLPを通過させる。
$z’^{(l)}_{(p,t)} = W_O \begin{bmatrix}
s^{(l,1)}_{(p,t)} \\
\vdots \\ s^{(l,\mathcal{A})}_{(p,t)}
\end{bmatrix} + z^{(l-1)}_{(p,t)}(8) $
$z^{(l)}_{(p,t)} = MLP(LN(z’^{(l)}_{(p,t)})) + z’^{(l)}_{(p,t)} (9)$
Classification embedding
最終的なclip埋め込みは、分類トークンの最終ブロックから得られる。
$y = LN(z^{(L)}_{(0.0)}) \in \mathbb{R}^D (10)$
この表現の上に1層のMLP隠れ層を追加し、最終的な動画クラスの予測に使用する。
Space-Time Self-Attention Models
式5の時空間的なattentionを各フレーム内の空間的なattentionのみに置き換えることで、計算コストを削減できる(式6)。しかし、このようなモデルでは、フレーム間の時空間依存性を考慮する必要がない。完全な時空間attentionと比較すると、特に強力な時空間モデルが必要なベンチマークでは、分類精度が低下する。
より効率的な構造として、時間的attentionと空間的attentionを別々に適用するDivided Space-Time Attention (T+S)を提案する。
Divided Space-Time AttentionをSpaceとJoint Space-Time Attentionと比較したのが下のfig1.
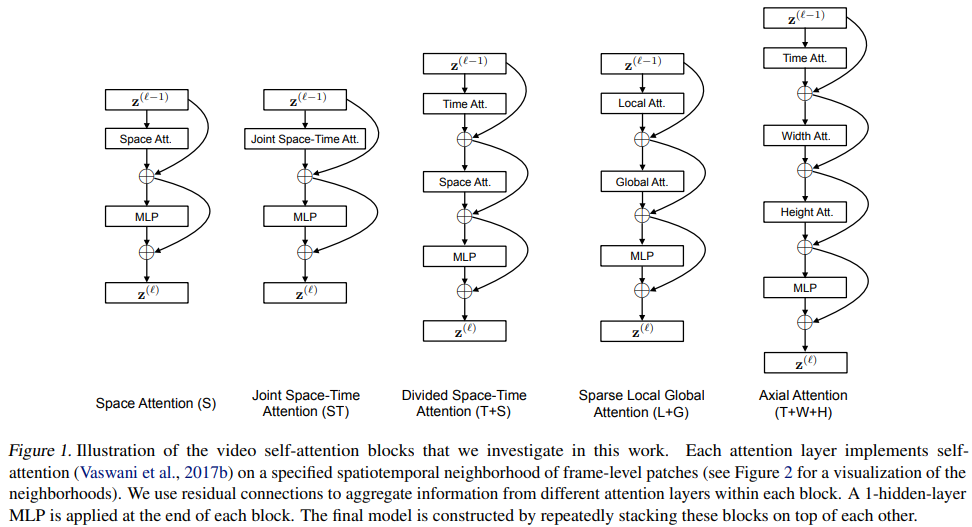
また、それぞれのattentionモデルを動画の例で視覚化したものがfig2である。

Divided Attentionでは、各ブロック$l$のなかでまず、各パッチ$(p,t)$を他のフレームの同じ空間的位置にあるすべてのパッチと比較して時間的なattentionを計算する。
$\alpha ^{(l,a)time}_{(p,t)} = SM(\frac{q^{(l,a)}_{(p,t)}} {\sqrt{D_h}}^T \cdot [k^{(l, a)}_{(0,0)} \{ k^{(l,a)}_{(p,t’)}\}_{t’=1,…F }]) (11)$
時間的attentionを用いて式8を適用して得られたencoding $z’^{(l)time}_{(p,t)}$は、MLPに渡される代わりに空間的attentionの計算にフィードバックされる。
つまり、$z’^{(l)time}_{(p,t)}$から新たなkey, query, valueベクトルを得て、式6を用いて空間的attentionを計算する。最後に得られたベルトル$z’^{(l)space}_{(p,t)}$が式9のMLPに渡され、ブロック$l$におけるパッチの最終的なencoding$z’^{(l)}_{(p,t)}$が計算される。
divided attentionモデルでは、時間と空間の次元に渡って異なるquery, key, value行列$\{ W^{(l,a)}_{Q^{time}},W^{(l,a)}_{K^{time}},W^{(l,a)}_{V^{time}}\}$と$\{ W^{(l,a)}_{Q^{space}},W^{(l,a)}_{K^{space}},W^{(l,a)}_{V^{space}}\}$を学習する。また、式5の時空間共同attentionモデルでは、パッチごとに(NF+1)回の比較が必要であるのに対し、deivided attentionでは、パッチごとに(N + F + 2)回の比較しか行わない。効率的であるだけでなく、精度の向上にもつながった。
- Sparse Local Gloval attention model(L+G)
- Axial attention model(T+W+H)
についても実験を行った。モデルの構造は、fig1,注目されるパッチについてはfig2に示す。
(L+G)はまず、各パッチ$(p,t)$に対して、隣接する$F\times H/2\times W/2$パッチを考慮してlocal attentionを計算する。次に、時間次元と2つの空間次元に沿って2パッチのストライドを使用してクリップ全体に渡ってスパースなグローバルattentionを計算する。したがって(Child et al., 2019)で用いられているのと同様に、local-global 分解とスパースパターンを用いた完全な時空間的attentionのより高速な近似とみなすことができる。
Axial attentionは、attentionの計算を時間、幅、高さの異なるステップで分解する。画像の2つの空間軸に渡る分解されたattentionパターンは(Ho et al., 2019; Huang et al., 2019;Wang et al., 2020b) で提案されており、我々の(T+W+H)は、動画の場合には、3つ目の次元(時間)を追加する。
これらのモデルは、いずれも各ステップごとに異なるquery, key, valueを学習することで実装されている。
4. Experiments
4つの人気のある行動認識データセットで、TimeSformerを評価する。
- Kinetics-400
- Kinetics-600
- Something-Something V2
- Diving-48
- すべての実験において、ImageNetで事前学習したBase ViTモデル構造を採用。
- 特に指定がない場合サイズが8x224x224のクリップを使用。
- フレームは116のレートでサンプリング
- パッチサイズ16×16ピクセル
- 推論時には、特に指定がない場合動画の中央にある1つの時間的クリップをサンプリングする。動画クリップ全体がカバーされるように、3つの空間クロップ(左下、中央、右下)を使用
- 最終的な予測は、これら3つの予測のsoftmax scoreを平均することで得られる。
4.1. Analysis of Self-Attention
fig1にベンチマークとしてKinetics-400, Something-Something-V2を用いて、TimeSformerで提案された5つの時空間attention の結果を示している。
- 空間のみattention(S)
- K400で良好なパフォーマンス
- (Sevilla-Lara et al, 2021)では、空間情報の利用が、時間的なダイナミクスの活用よりも重要であると発見。
- SSv2では、低い結果。
- このデータセットにおける時間的モデリングの重要性を強調
- K400で良好なパフォーマンス
- divided attention
- K400,SSv2の両方でSOTA
- 時間的attention, 空間的attenitonのための個別の学習パラメータを含んでいるため、より大きな学習容量を持っているため。
fig3では、より高い空間解像度(左)とより長い動画(右)を用いた場合に、時空間統合型と時空間分割型(divided space-time)のattention計算コストを比較。
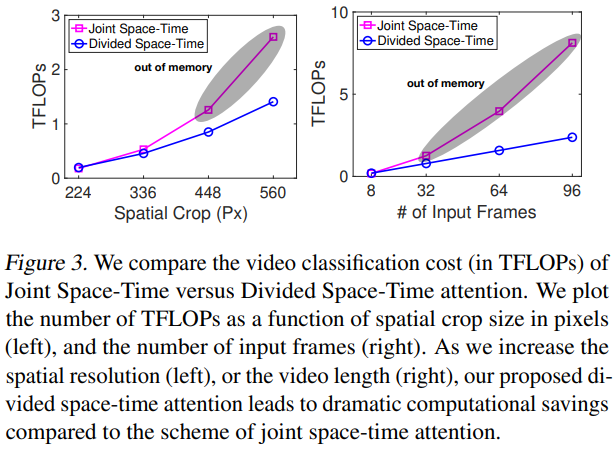
- 時空間分割
- どちらの設定でも問題なくスケーリング
- 時空間結合
- 解像度や、動画の長さが長くなると、コストが劇的に高くなる。
- 解像度448ピクセルまたはフレーム数32超えると、GPUメモリのオーバーフロー。
時空間分割のほうが効率的なので、以降のすべての実験は、時空間分割のTimeSformerを使用。
4.2. Varying the Number of Tokens in Space and Time(空間と時間におけるトークン数の変化)
提案モデルは、多くの3DCNNと比較して、高解像度、長い動画でも動作する。これらは、Tramsformerに供給されるトークンのシーケンスの長さに影響する。
- 空間解像度を高くするとフレームあたりのパッチ数(N)が多くなる。
- フレーム数を増やすと入力トークンの数も増える。
上の2つの軸に沿ってトークン数を別々に増やす実験を行った。結果をfig4に示す。
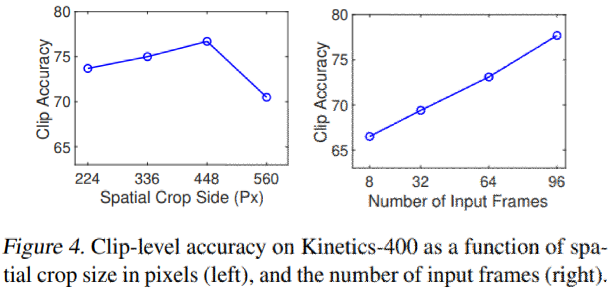
- ある時点までの空間分解能を上げると、性能が大幅に向上する。
- 入力クリップの長さを長くすると、一貫して精度が向上する事が確認できる。
- GPUのメモリ制限によって96フレームまで(一般的なCNNモデルは、8~32フレーム)
4.3. The Importance of Pretraining and Dataset Scale(事前学習とデータセット規模の重要性)
最近の研究で、Dosovitskiy らは、ViTは非常に大きなデータセットで学習したときに最も効果的であることを実証した。
このセクションでは、この傾向がTimeSformerモデルにも同じ傾向があるかどうかを調査する。
- ImageNetのpretrainを行わずに動画データセットで直接TimeSformerを学習させる。
- Touvronらのtraining-from-scratchプロトコルに従い、いくつかのバリエーションも評価
- 意味のある特徴を学習できなかった。
- K400とSSv2の異なるサブセット(全データの{25%,50%, 75%, 100%})でモデルを学習した。
- 同じサブセットで学習したSlowFast R50 及び I3D R50とも比較
- ImageNetで事前学習。
- 結果をfig5に示す。
- K400においてTimeSformerはすべての訓練サブセットで他のモデルよりも優れている。
- SSv2では、全データの75% or 100%で学習した場合のみ最高精度。
- 効果的に学習するためには、より多くの例が必要?
4.4. Comparison to the State-of-the-Art(最新技術との比較)
一般的な行動認識データセットにおいて、TimeSformerを最新技術と比較する。モデルには3種類のversionがある。
- TimeSformer(8x224x224の動画クリップで動作するモデルのdefault ver)
- TimeSformer-HR(16x448x448の動画クリップで動作する高空間解像度ver)
- TiemSformer-L(96x224x224の動画クリップで動作するフレームを1/4のレートでサンプリングする長距離構成)
Kinetics-400
Table2にK400の検証セットでの結果を示す。精度評価に加えて、推論コストをTFLOPs単位で示す。
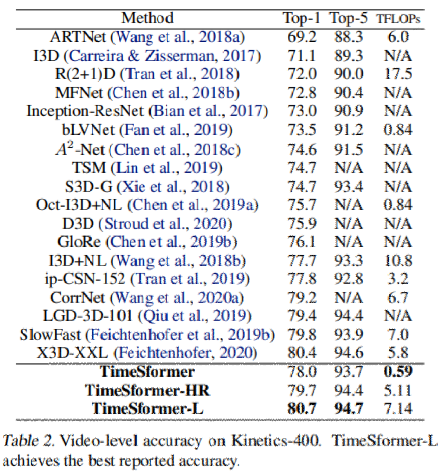
- これまでの手法では、推論の際に10個の時間的クリップと3個の空間的クロップ(合計30個の時空間的view)を使用。
- TiemSformerは、3個のview(3個の空間的クロップ)のみで確かな精度を達成。
- TimeSformer-Lは80.7%のtop1精度を達成。
- default TimeSformerは最近の最新モデルの中で最も低い推論コストで78%
fig6では、推論の際に複数の時間的クリップを使用した場合の効果を調べた(それぞれが1つの空間的クロップを持つ)。
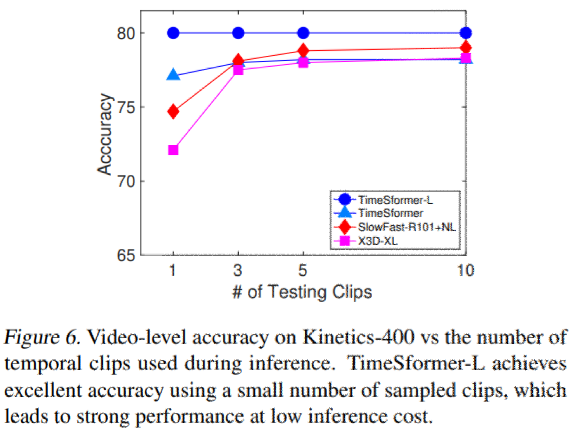
- X3DとSlowFastは、最高精度に近づくために複数(>=5)のクリップを必要とする。
- TimeSformerは、複数のクリップを使用することによるメリットはない。
- Kineticsの約12秒を1つのクリップで処理できることから。
- ImageNetで事前学習したときの学習速度が早い。
- K400上でSlowFast 8×8 R50を訓練するには、64GPUで54.3時間
- K400上でI3D R50を訓練するには、32GPUで45時間
- K400上でTimeSformerを訓練するには、32GPUで14.3時間(3分の1)
Kinetics-600
Table3にKinetics-600での結果を示す。
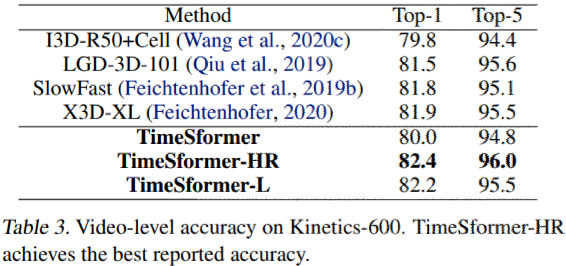
すべての先行研究を凌駕、最高のパフォーマンスを示したのはTimeSformer-HRであることに注目。
Something-Something-V2
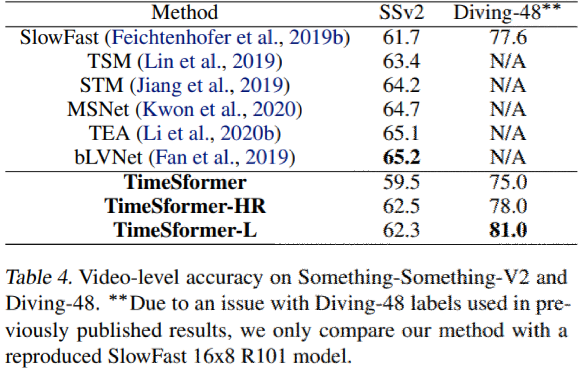
Table4にSSv2での結果を示す。
他の最良モデルよりも低い精度を示したが、有望なアプローチで有ることを示唆。
Diving-48
時間的に重いデータセットであるDiving-48での結果をTable4に示す。
SlowFastをかなりのマージンで上回る事を示した。(前のdataset verでラベルの問題があったためslowfastは再現結果)
4.5. Long-Term Video Modeling (長期的な動画モデリング)
How to 100Mデータセットを使用して、長期的な動画モデリングのタスクでTimeSformerを評価する。
- How to 100Mとは
- 大規模な教育動画のデータセット
- 料理、修理、編み物、芸術作品の制作など23K以上の異なるタスクを人間が行う様子を撮影。
- 約100万本の教育用Web動画
- 平均再生時間7分
- 各動画にタスクのラベルが1つついている。
今回は、少なくとも100の動画例をもつカテゴリのみを考慮する。
- 今回の評価用サブセット
- 1059のタスクカテゴリ
- 120Kの動画
- 85Kの訓練用動画と35Kのテスト用動画に分割
結果をTable5に示す。
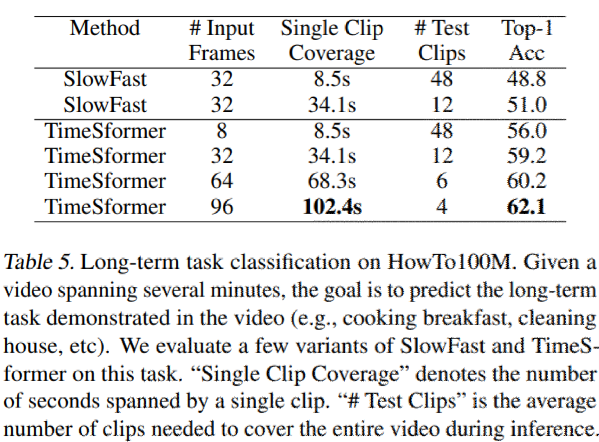
- baselineとして、SlowFast R50の2つのバージョンを使用。
- 32フレームの入力(最初のバージョンは、サンプリングレート18なので約8秒の長さのクリップ)
- TimeSformerではフレームレート132でサンプリングされた動画クリップ使用
- 8, 32, 64, 96のフレーム数を持つ4つの種類でテスト
- 入力時間範囲を完全にカバーするために重複しない時間クリップをサンプリング(1クリップ8.5sなら410sの動画は、48個のテストクリップサンプリング)
- 動画レベルの分類は、クリップの予測値を平均することで行う。
- TiemSformerは、SlowFastを7~8%の大差で上回る。
- 距離の長いversionが一番良い精度
- 動画backboneの上で動作する長期モデルを組み合わせることでより良い結果が得られる可能性がある。
5. Conclusion
- 畳み込みベースの手法とは根本的に異なるアプローチであるTiemSformerを提案。
- 時空間のself-attentionのみで構成された効果的でスケーラブルな構造を設計することが可能であることを示した。
- 本手法の特徴は、以下の通り
- 概念的にシンプル
- 主要な行動認識ベンチマークで最先端の結果を達成
- 推論コストが低い
- 長期的な動画モデリングに適している
- 将来的には、行動定位、動画キャプション、質問応答など他の動画解析タスクにも拡張する予定。